구조적 스트리밍
- 개요
- 빠른 예제
- 프로그래밍 모델
- Dataset과 DataFrame을 사용하는 API
- 연속 처리 모드
- 기타 자료
개요
구조적 스트리밍은 스파크 SQL 엔진을 기반으로 개발된 확장성 있고 장애를 허용(fault-tolerant)하는 스트림 처리 엔진입니다. 정적 데이터에 대한 배치(batch) 연산을 정의하는 것과 같은 방법으로 스트리밍 연산을 정의할 수 있습니다. 스파크 SQL 엔진은 스트리밍 데이터가 계속 도달하는 동안 구조적 스트리밍의 실행 상태를 지속적으로 체크하여 점진적으로 최종 결과를 업데이트합니다. Scala, Java, Python이나 R에서 Dataset/DataFrame API를 사용하여 스트리밍 집계, 이벤트-시간 윈도우, 스트림-배치 조인 등을 표현 할 수 있으며, 이렇게 주어진 연산은 배치 방식 연산과 마찬가지로 최적화된 스파크 SQL 엔진에서 실행됩니다. 마지막으로, 시스템은 체크포인트와 로그 선행 기입(Wrtie-Ahead Log)을 통해 장애 발생시에도 종단간 정확히 한 번(exactly-once) 데이터 처리를 보장합니다. 요약하자면, 구조적 스트리밍은 빠르고, 확장 가능하고, 장애를 허용하며, 유저가 스트리밍에 대해 신경쓰지 않더라도 종단 간에 정확히 한 번만 데이터를 처리하는 스트림 프로세싱입니다.
내부적으로, 구조적 스트리밍 쿼리는 마이크로 배치(batch) 프로세싱 엔진을 이용해 처리되는 것이 기본 설정입니다. 이 엔진은 주어지는 입력 스트림을 작은 배치 작업의 연속으로 처리함으로써 100밀리초 가량의 종단간 지연 속도와 함께 장애 발생시에도 정확히 한 번(exactly once) 데이터 처리를 보장합니다. 그러나 스파크 2.3 버전부터, 장애 발생시 데이터 처리 보장 수준을 최소 한 번(at-least-once)으로 낮춘 대신 1밀리초 수준의 지연 속도를 가지는 모드인 연속 처리 (Continuous Processing) 모드가 추가되었습니다. 쿼리의 Dataset/DataFrame 연산을 바꾸지 않고도 애플리케이션 요구 사항에 맞게 모드를 선택할 수 있습니다.
이 가이드에서는 여러분에게 구조적 스트리밍의 프로그래밍 모델과 API를 소개할 것입니다. 기본적으로 사용되는 마이크로 배치 처리 모델을 이용하여 대부분의 개념을 설명할 것이며, 그 다음에 (실험적인 기능인) 연속 처리 모델을 설명할 것입니다. 먼저 구조적 스트리밍 쿼리의 간단한 예제인 스트리밍 단어 개수 세기로 시작해봅시다.
빠른 예제
TCP 소켓을 통해 데이터 서버로부터 받은 텍스트 데이터에 포함된 단어의 수를 세는 연산을 계속해서 실행하고 싶다고 해보겠습니다. 구조적 스트리밍을 이용하여 이를 표현하는 방법을 살펴보겠습니다. Scala/Java/Python/R에서 전체 코드를 볼 수 있습니다. 스파크를 다운로드하면 직접 예제를 실행해볼 수 있습니다. 어떤 경우에서든, 예제를 한 단계씩 잘 살펴보고 어떻게 동작하는지를 이해해봅시다. 먼저 필수 클래스를 임포트해서 모든 스파크 관련 기능의 시작점인 로컬 SparkSession을 만들어야 합니다.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()다음으로, localhost:9999 서버에서 받은 텍스트 데이터를 표현하는 스트리밍 DataFrame을 만들고 DataFrame을 변환하여 단어 수를 계산합니다.
// localhost:9999 연결에서 주어지는 입력 라인의 스트림을 나타내는 DataFrame을 생성
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// 라인을 단어로 분할
val words = lines.as[String].flatMap(_.split(" "))
// 단어별 개수
val wordCounts = words.groupBy("value").count()이 lines DataFrame은 스트리밍 텍스트 데이터를 포함하는 무한한 테이블(unbounded table)을 나타냅니다. 이 테이블은 “value”라는 문자열 컬럼 하나를 포함하고 있으며, 스트리밍 텍스트 데이터의 각 라인은 테이블의 로우가 됩니다. 아직 변환 연산을 정의했을 뿐, 시작하지는 않았으므로 어떠한 데이터도 실제로는 수신하지 않습니다. 다음으로 .as[String]을 사용하여 DataFrame을 문자열 Dataset으로 변환해서 각 라인을 여러 단어로 분할하는 flatMap 연산을 적용할 수 있습니다. 결과 words Dataset에는 모든 단어가 포함됩니다. 마지막으로 Dataset의 고유한 값을 기준으로 그룹화하고 그 개수를 셈으로써 wordCounts DataFrame을 정의합니다. 이 DataFrame은 실시간으로 업데이트되는 스트림에 포함된 단어의 수를 나타냅니다.
# localhost:9999 연결에서 주어지는 입력 라인의 스트림을 나타내는 DataFrame을 생성
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# 라인을 단어로 나누기
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# 단어별 개수
wordCounts = words.groupBy("word").count()이 lines DataFrame은 스트리밍 텍스트 데이터를 포함하는 무한한 테이블(unbounded table)을 나타냅니다. 이 테이블은 “value”라는 문자열 컬럼 하나를 포함하고 있으며, 스트리밍 텍스트 데이터의 각 라인은 테이블의 로우가 됩니다. 현재 변환을 설정하는 것뿐이고 아직 시작하지 않았으므로 어떠한 데이터도 수신하지 않습니다. 다음으로, 내장 SQL 함수 두 개(split과 explode)를 사용하여 각 라인을 단어를 하나씩 포함하는 로우 여러 개로 분할합니다. 또한 새로운 컬럼을 “word”로 이름 붙이기 위해 alias함수를 사용합니다. 마지막으로 Dataset의 고유한 값을 기준으로 그룹화하고 이를 계산하여 wordCounts DataFrame을 정의합니다. 이는 스트림의 실행 단어 수를 나타내는 스트리밍 DataFrame입니다.
지금까지 스트리밍 데이터에 대한 쿼리를 설정했습니다. 남은 것은 실제로 데이터를 받고 단어 수 계산을 시작하는 것입니다. 이를 위해, 업데이트될 때마다 ( outputMode("complete")로 명시된) 전체 단어 수를 콘솔에 출력하도록 설정합니다. 그리고 난 후 start()를 사용하여 스트리밍 계산을 시작합니다.
// 실행 단어 수를 콘솔에 출력하는 쿼리를 시작
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()# 실행 단어 수를 콘솔에 출력하는 쿼리를 시작
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()이 코드가 실행되고 나면, 백그라운드에서 스트리밍 계산이 시작될 것입니다. query 객체를 이용하여 해당 활성 스트리밍 쿼리를 제어할 수 있으며, 쿼리가 활성화되어있는 동안 프로세스가 종료되지 않도록 awaitTermination()을 사용하여 쿼리가 종료될 때까지 기다립니다.
이 예제 코드를 실제로 실행하려면, 여러분의 스파크 애플리케이션에서 코드를 컴파일하거나, 스파크를 다운로드 한 후에 예제를 실행하면 됩니다. 지금은 후자를 보여주고 있습니다. 먼저 다음을 이용하여 Netcat(대부분의 Unix 계열 시스템에서 발견되는 작은 유틸리티)을 데이터 서버로 실행해야 합니다.
$ nc -lk 9999
다음으로, 다른 터미널에서 다음 명령어를 이용하여 예제를 실행할 수 있습니다.
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999$ ./bin/spark-submit examples/src/main/python/sql/streaming/structured_network_wordcount.py localhost 9999이제, netcat 서버를 실행하는 터미널에 입력되는 모든 라인 수가 계산되어 매초 화면에 출력될 것입니다. 이는 다음과 같이 보일 것입니다.
|
|
프로그래밍 모델
구조적 스트리밍의 핵심 아이디어는 실시간으로 주어지는 데이터 스트림을 무한히 데이터가 추가되는 테이블과 같이 취급하는 것입니다. 이 아이디어는 배치 프로세싱 모델과 매우 유사한 새로운 스트림 프로세싱 모델로 이어집니다. 스트리밍 계산을 정적 테이블에서의 표준 배치 쿼리(standard batch-like query)와 같이 다룰 것이며, 스파크는 이를 무한한 크기의 입력 테이블(unbounded input table)에 점진적으로 추가하는 증분(incremental) 쿼리를 실행합니다. 이 모델을 더 자세히 알아봅시다.
기본 개념
입력 데이터 스트림을 “입력 테이블”이라고 가정해봅시다. 스트림에 도달하는 모든 데이터 아이템은 입력 테이블에 추가되는 새로운 로우와 같습니다.

입력에 있는 쿼리는 “결과 테이블”을 만들어 낼 것입니다. 모든 트리거 간격 (예 : 1초마다) 마다 새로운 로우가 입력 테이블에 추가되고 결과적으로 테이블을 업데이트합니다. 결과 테이블이 업데이트될 때마다 변경된 결과 로우를 외부 싱크에 기록해야 합니다.
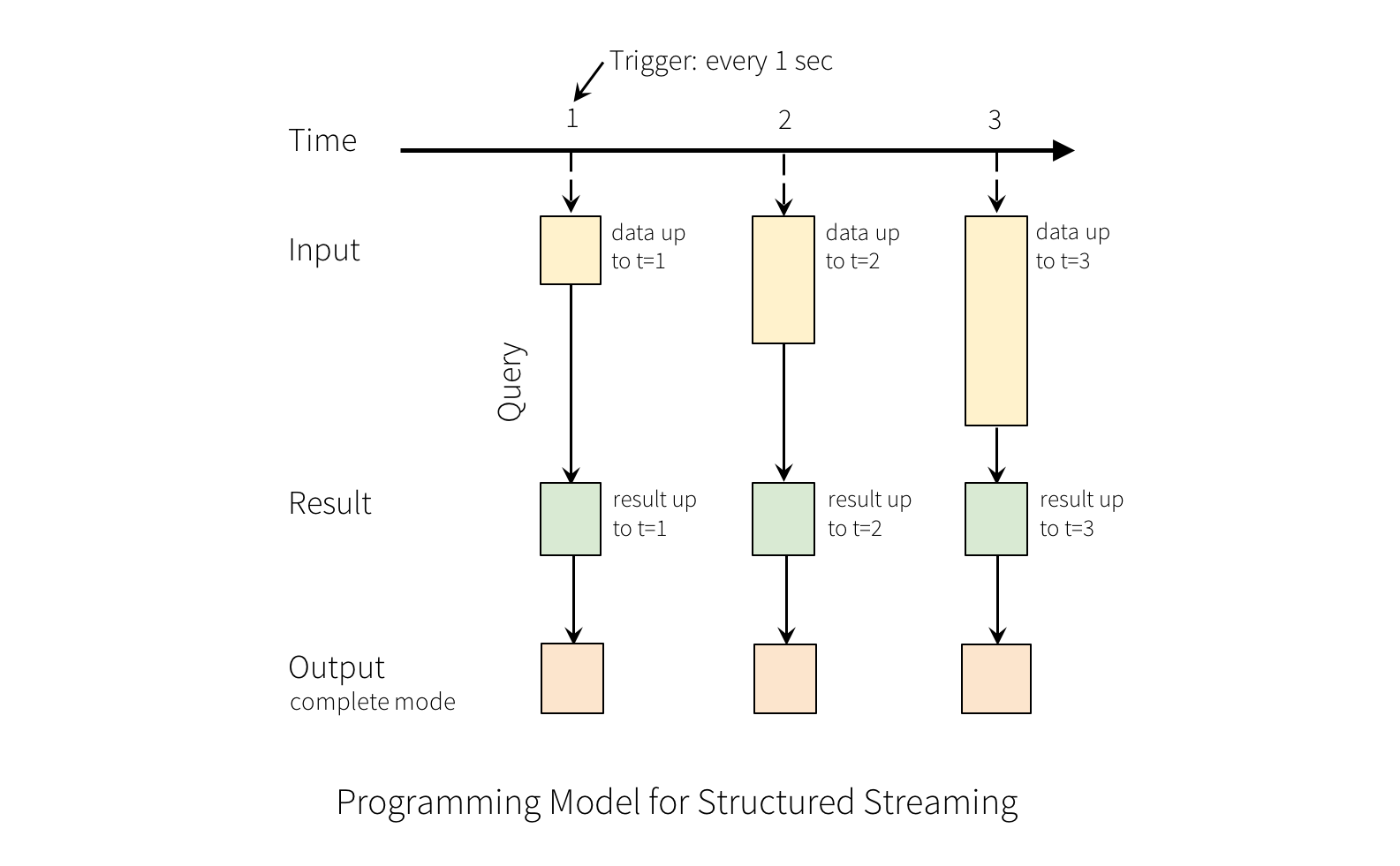
“출력”은 외부 저장소에 쓰여지는 것이라고 정의할 수 있습니다. 구체적인 출력 방법은 출력 모드에 따라 달라집니다:
-
완료 모드 (Complete Mode) - 업데이트된 결과 테이블 전체가 외부 저장소에 쓰여집니다. 저장소 커넥터에 따라 전체 테이블의 쓰기를 처리하는 방법이 결정됩니다.
-
추가 모드 (Append Mode) - 마지막 트리거가 외부 저장소에 기록된 이후에 추가된 새 로우만 결과 테이블에 추가됩니다. 이는 결과 테이블의 기존 로우를 변경하지 않는 쿼리에만 적용 가능합니다.
-
업데이트 모드 (Update Mode) - 마지막 트리거 이후, 결과 테이블에서 업데이트된 로우만이 외부 저장소에 기록됩니다 (Spark 2.1.1부터 사용 가능). 이 모드는 마지막 트리거 이후 변경된 로우만 출력한다는 점에서 완료 모드와 다릅니다. 쿼리에 집계가 포함되어 있지 않는 경우에는 추가 모드와 동일합니다.
각 모드가 사용될 수 있는 쿼리 종류에는 제한이 있습니다. 이에 대해, 나중에 자세히 설명하겠습니다.
이 모델의 사용법을 설명하기 위해, 위 예제의 맥락에서 이 모델을 설명해 보겠습니다. 첫 번째 lines DataFrame은 (무한한 크기의) 입력 테이블에, 마지막 wordCounts DataFrame은 결과 테이블에 해당합니다. 여기서 눈여겨 보아야 할 부분은 스트리밍 DataFrame인 lines 에서 wordCounts를 생성하기 위해 적용되는 쿼리가 같은 작업을 정적 DataFrame에 수행할 때와 완전히 동일하다는 점입니다. 다만 정적 Dataframe의 경우와는 달리, 이 쿼리가 시작되면 스파크는 소켓 연결로부터 새로운 데이터가 주어지는지 계속해서 확인합니다. 그리고 새로운 데이터가 주어지는 경우 스파크는 이전까지 계산된 단어별 개수와 새 데이터를 결합하여 업데이트된 개수를 계산하는 “증분(incremental)” 쿼리를 실행합니다. (아래 그림 참조).
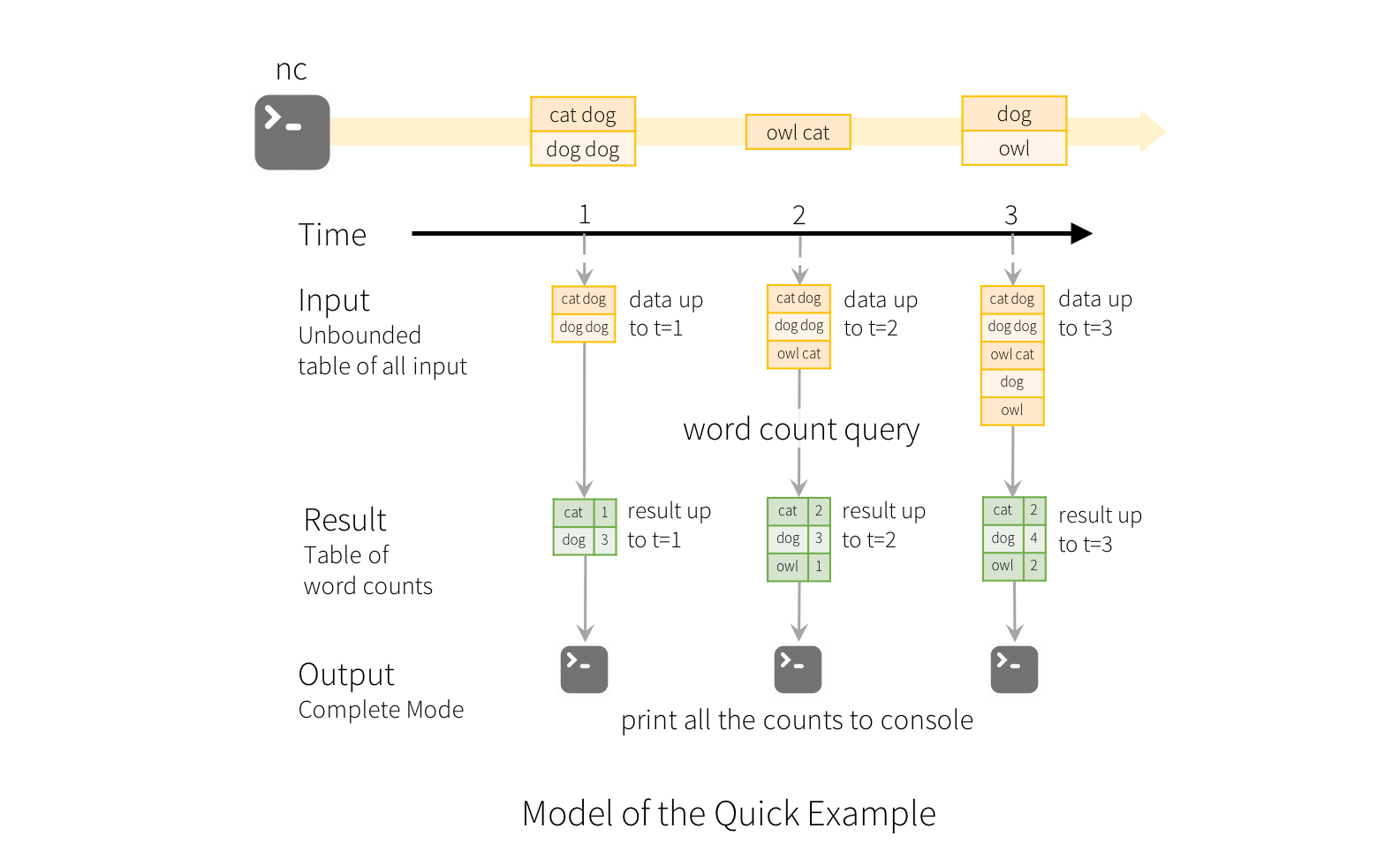
구조적 스트리밍은 전체 테이블의 상태를 계속해서 유지(혹은 보유)하지 않는다는 점을 명심하시기 바랍니다. 스파크 스트리밍은 스트리밍 데이터 소스에서 사용 가능한 최신 데이터를 읽어와서 이를 처리하고, 결과를 점진적으로 업데이트(incrementally update)한 뒤 소스에서 읽어 온 데이터를 파기하는 식으로 동작합니다. 즉, 결과를 업데이트하는 데 필요한 최소한의 중간 상태 데이터(intermediate data)만 유지합니다. (예 : 이전 예제의 중간 카운트).
이 모델은 다른 스트림 프로세싱 엔진들과 확연하게 다릅니다. 많은 스트리밍 시스템에서 사용자는 장애 허용(fault-tolerance) 및 데이터 일관성(최소 한 번(at-least-once), 최대 한 번(at-most-once), 정확히 한 번(exactly-once)) 등을 고려하며 집계 실행을 유지해야 합니다. 이 모델의 경우 스파크가 새로운 데이터가 있을 때 결과 테이블을 업데이트하므로 사용자가 이 부분에 대해 신경쓸 필요가 없습니다. 그 예로써, 이 모델이 이벤트 시각 기반 프로세싱을 수행하는 방법 그리고 지연된 데이터를 다루는 방법을 살펴보겠습니다.
이벤트 시각과 지연 데이터 처리
이벤트 시각은 데이터 자체에 포함된 시간입니다. 많은 애플리케이션에서, 이벤트 시각에서 작업하고 싶은 경우가 있을 것입니다. 예를 들어, 1분마다 IoT 장치에서 생성되는 이벤트의 수를 구하려면, 스파크에서 수신하는 시각이 아닌 데이터가 생성된 시각(즉, 데이터의 이벤트 시각)을 사용하게 될 것입니다. 이러한 이벤트 시각은 이 모델에서 매우 자연스럽게 표현됩니다. 장치의 각 이벤트는 테이블의 로우이며 이벤트 시각은 그 로우의 컬럼 값입니다. 이러한 접근 방법은 윈도우 기준 집계(window-based aggregation)를 이벤트 시각 컬럼에 대한 그룹화 혹은 집계 연산의 특별한 형태로 취급할 수 있게 합니다 - 각 시간 윈도우는 그룹이 되고, 각각의 로우는 1개 이상의 윈도우(혹은 그룹)에 속할 수 있는 식입니다. 바로 이러한 이유 때문에, 이벤트 시간 윈도우 기준 집계를 수행하는 쿼리는 정적 Dataset과 스트리밍 Dataset 모두에서 동일하게 정의될 수 있는 것입니다 - 사용자 입장에서는 훨씬 쉽게 사용할 수 있습니다.
뿐만 아니라, 이 모델은 이벤트 시각을 기준으로 예상보다 늦게 도착한(=처리 시각과 이벤트 시각의 차이가 예상보다 큰, 혹은 처리 시각이 예상보다 늦어진) 데이터도 자연스럽게 다룰 수 있습니다. 스파크가 결과 테이블을 업데이트 하는 방식으로 동작하기 때문에, 유지하고 있는 중간 상태(intermedate state) 데이터가 무한히 커지지 않도록 오래된 집계 결과를 파기하는 것과 마찬가지로 늦게 도착한 데이터를 오래된 집계 결과에 업데이트 해주기만 하면 되기 때문입니다. 스파크 2.1부터는 사용자가 지연 데이터가 얼마까지 지연될 수 있는지 임계 값을 지정하고 엔진이 이에 따라 이전 상태를 정리하는 워터 마킹 기능을 지원합니다. 자세한 내용은 윈도우 연산 섹션에서 설명합니다.
장애 허용의 의해
구조적 스트리밍 디자인의 핵심 목표 중 하나는 종단간 ‘정확히 한 번 전달’ 을 구현하는 것이었습니다. 이를 위해 프로세스의 정확한 진행 상황을 안정적으로 추적해서 장애가 발생했을 때 재시작 혹은 재처리만으로 문제를 해결할 수 있도록 구조적 스트리밍 소스, 싱크 및 실행 엔진을 설계했습니다. 모든 스트리밍 소스는 스트림의 읽기 위치를 추적하기 위해 (Kafka 오프셋 또는 Kinesis 시퀀스 숫자와 유사한) 오프셋을 갖는다고 가정합니다. 엔진은 체크포인팅(checkpointing)이나 선행 기입 로그(write-ahead logs)를 사용하여 각 트리거에서 처리되는 데이터의 오프셋 범위를 기록합니다. 스트리밍 싱크는 재처리를 위해 멱등성이 있도록(idempotent) 설계되었습니다. 구조적 스트리밍은 이렇게 원하는 지점에서부터 다시 이벤트를 받아올 수 있는 소스와 멱등성이 있는 싱크를 함께 사용함으로써 종단 간 정확히 한 번 전달(exactly once delivery)을 보장할 수 있습니다.
Dataset과 DataFrame을 사용하는 API
스파크 2.0 버전부터는 DataFrame과 Dataset을 사용해서 정적(static)으로 주어지는 유한한 크기의 데이터(bounded data) 뿐만 아니라 스트리밍(streaming) 방식으로 주어지는 무한한 크기의 데이터(unbounded data) 역시 표현할 수 있습니다. SparkSession (Scala/Java/Python/R 문서)를 사용해서 스트리밍 소스에서 스트리밍 DataFrame/Dataset을 만들 수 있으며, 여기에 정적 Dataset/DataFrame과 동일한 연산을 적용할 수도 있습니다. Dataset/DataFrame에 대해 잘 모르신다면 DataFrame/Dataset 프로그래밍 가이드를 먼저 참고하시는 것을 권장합니다.
스트리밍 DataFrame과 스트리밍 Dataset 만들기
스트리밍 DataFrame은 SparkSession.readStream()이 반환하는 DataStreamReader 인터페이스(Scala/Java/Python 문서)를 이용하여 만들 수 있습니다. R에서는 read.stream() 메소드를 이용하여 만들 수 있습니다. 정적 Dataframe을 생성하기 위한 읽기(read) 인터페이스와 비슷한 방법으로 데이터 형식, 스키마, 옵션 등 세부 사항을 지정할 수 있습니다.
입력 소스
몇 가지의 내장 소스가 있습니다.
-
파일 소스 - 디렉토리에 있는 파일을 데이터 스트림으로 읽어 옵니다. 텍스트, csv, json, orc, parquet 파일 형식이 지원됩니다. 최신 버전에서 지원되는 파일 형식 목록과 각 파일 형식에 대해 지원되는 옵션에 대해서는 DataStreamReader 인터페이스 문서를 확인하세요. 각 파일은 해당 디렉토리에 원자적으로(automically) 이동되어야 한다는 점을 주의하시기 바랍니다. 대부분의 파일 시스템에서 이는 file move 명령으로 가능합니다.
-
Kafka 소스 - Kafka에서 데이터를 읽어 옵니다. Kafka 브로커 버전 0.10.0 이상에서 호환됩니다. 자세한 사항은 Kafka 통합 가이드를 참조하세요.
-
소켓 소스 (테스트용) - 연결된 소켓으로부터 UTF-8 텍스트 데이터를 읽어 옵니다. 리스닝 서버 소켓은 드라이버에 있습니다. 소켓 소스는 테스트 용으로만 사용되어야 한다는 점에 주의하세요. 이는 종단간 장애 허용(fault-tolerant)을 보장하지 않습니다.
-
속도 소스 (테스트용) - 초당 생성될 로우의 수를 지정하면 그것에 맞게 데이터를 생성합니다. 각 로우는
timestamp와value값을 포함합니다.timestamp는Timestamp타입으로 메시지가 생성된 시각을 의미하고,value는Long타입의 메시지 수이며, 첫 로우는 0부터 시작합니다. 이 소스는 테스트와 벤치마크용입니다.
몇몇 소스는 장애 발생시 체크포인트된 오프셋을 이용한 데이터의 재연 가능성을 보장하지 않기 때문에 장애를 허용하지 않습니다. 앞에 나온 장애 허용 의미 구조에 대한 섹션을 참조하세요. 다음은 스파크에 내장되어 있는 소스에 대한 세부 사항입니다.
| 소스 | 옵션 | 장애 허용 | 비고 | ||||
|---|---|---|---|---|---|---|---|
| 파일 소스 |
path: 입력 디렉토리의 경로. 모든 파일 형식에 공통임.
maxFilesPerTrigger: 트리거가 호출될 때마다 주어지는 최대 파일 수. (기본값: no max)
latestFirst: 최신 파일을 먼저 처리할지의 여부. 큰 백로그 파일이 있을 때 유용함. (기본값: false)
fileNameOnly: 새 파일을 전체 경로가 아닌 파일 이름만으로 확인할지의 여부. (기본값: false). 이 값을 ‘true’로 설정하면, 다음 파일들은 파일 이름이 “dataset.txt”로 같으므로 같은 파일로 간주됩니다:
"file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" 특정 파일 형식에 대한 옵션은 DataStreamReader(Scala/Java/Python/R)에서 관련 메소드를 확인하세요.
예를 들어, "parquet" 형식의 옵션에 대해서는 DataStreamReader.parquet()을 확인하세요.
첨언하자면, 특정 파일 형식에 영향을 주는 세션 설정이 있을 수 있습니다. 자세한 내용은 SQL 프로그래밍 가이드를 참조하세요. 예를 들어, "parquet"은 Parquet 설정 섹션을 확인하세요. |
예 | glob 경로를 지원합니다. 쉼표로 구분된 경로와 glob은 지원하지 않습니다. | ||||
| 소켓 소스 |
host: 연결할 호스트, 필수.port: 연결할 포트, 필수.
|
아니오 | |||||
| 고정 속도 소스 |
rowsPerSecond: 초당 생성될 로우의 수. (예: 100, 기본값: 1)rampUpTime: 생성 속도가 rowsPerSecond가 되기까지의 소요 시간. 초보다 더 작은 단위를 사용하면 정수 단위로 절삭됩니다. (예: 5s, 기본값: 0s)numPartitions 생성될 로우의 파티션 수. (예: 10, 기본값: 스파크의 기본 병렬값.)이 소스는 rowsPerSecond에 도달하기 위해 최대한 시도하지만, 쿼리에 자원의 제한이 있을 수도 있습니다. 이때 numPartitions를 조절하면 목표 속도에 가까워질 수 있습니다.
|
예 | |||||
| Kafka 소스 | Kafka 통합 가이드를 확인하세요. | 예 |
아래는 몇 가지 예시입니다.
val spark: SparkSession = ...
// 소켓에서 텍스트를 읽어 옵니다
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // 스트리밍 소스를 가진 DataFrame이면 True를 반환합니다
socketDF.printSchema
// 디렉토리에 원자적으로 생성된 모든 csv 파일을 읽어 옵니다
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // csv 파일의 스키마를 지정합니다
.csv("/path/to/directory") // format("csv").load("/path/to/directory")와 동일합니다spark = SparkSession. ...
# 소켓에서 텍스트를 읽어 옵니다
socketDF = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
socketDF.isStreaming() # 스트리밍 소스를 가진 DataFrame이면 True를 반환합니다
socketDF.printSchema()
# 디렉토리에 원자적으로 생성된 모든 csv 파일을 읽어 옵니다
userSchema = StructType().add("name", "string").add("age", "integer")
csvDF = spark \
.readStream \
.option("sep", ";") \
.schema(userSchema) \
.csv("/path/to/directory") # format("csv").load("/path/to/directory")와 동일합니다이 예제들은 타입이 없는 스트리밍 DataFrame을 생성합니다. 즉, DataFrame의 스키마가 컴파일 타임에 확인되지 않고, 런타임에 쿼리가 제출된 후에 확인됩니다. map과 flatMap 등과 같은 연산은 컴파일 타임에 그 타입을 알고 있어야 합니다. 이와 같은 연산을 하기 위해서는 정적 DataFrame에서 사용한 방법과 동일한 방법으로, 타입이 없는 스트리밍 DataFrame을 타입이 있는 스트리밍 Dataset으로 변환하여야 합니다. 자세한 사항은 SQL 프로그래밍 가이드를 참조하세요. 지원되는 스트리밍 소스에 대한 자세한 내용은 문서의 뒷부분을 참조하세요.
스트리밍 DataFrame/Dataset의 스키마 추론과 파티션
기본적으로, 파일 기반 소스에서 동작하는 구조화된 스트리밍 처리는 스키마를 지정해야 합니다. 스파크의 자동 추론에 의존하는 것은 권장하지 않습니다. 이러한 제약은 장애가 발생했을 경우에도 스트리밍 쿼리에 일관된 스키마가 사용되는 것을 보장합니다. 임시로 스키마 추론을 사용할 경우에는 spark.sql.streaming.schemaInference를 true로 설정하여 활성화할 수 있습니다.
파티션 탐색은 /key=value/라는 이름의 하위 디렉토리가 있고, 디렉토리 탐색 과정에서 해당 디렉토리를 처리할 때 수행됩니다. 사용자가 제공한 스키마에 이러한 이름의 칼럼이 포함되어 있다면, 스파크가 자동으로 읽어 들이는 파일의 경로를 이용해 해당 컬럼의 값을 채웁니다. 파티션 스키마를 이루는 디렉토리는 쿼리가 시작할 때 존재해야 하며, 정적이어야 합니다. 예를 들어, /data/year=2015/가 존재할 때 /data/year=2016/를 추가하는 것은 괜찮지만, 파티션하는 컬럼을 바꾸는 것은 허용하지 않습니다 (예: /data/date=2016-04-17/라는 디렉토리 생성).
스트리밍 DataFrame/Dataset의 연산
여러 가지 연산을 DataFrame과 Dataset에 적용할 수 있습니다. 타입이 없는 SQL같은 연산에서 부터(예: select, where, groupBy), 타입이 있는 RDD같은 연산(예: map, filter, flatMap)까지 가능합니다. 자세한 내용은 SQL 프로그래밍 가이드를 참조하세요. 어떠한 연산이 가능한지 몇 가지 예시를 보며 함께 알아보겠습니다.
기본 연산 - 셀렉션, 프로젝션, 집계
DataFrame/Dataset에서 자주 사용되는 대부분의 연산은 스트리밍에서도 지원합니다. 지원하지 않는 몇 가지 연산은 이 섹션의 뒷부분에서 설명합니다.
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // { device: string, deviceType: string, signal: double, time: string }의 스키마를 갖는 IOT 장비의 스트리밍 DataFrame
val ds: Dataset[DeviceData] = df.as[DeviceData] // IOT 장비 데이터의 스트리밍 Dataset
// signal이 10 이상인 장비를 선택합니다
df.select("device").where("signal > 10") // 타입이 없는 API 사용
ds.filter(_.signal > 10).map(_.device) // 타입이 있는 API 사용
// 각 장비 타입에 대해 업데이트 횟수 세기
df.groupBy("deviceType").count() // 타입이 없는 API 사용
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // 타입이 있는 API 사용df = ... # { device: string, deviceType: string, signal: double, time: string }의 스키마를 갖는 IOT 장비의 스트리밍 DataFrame { device: string, deviceType: string, signal: double, time: string }
# signal이 10 이상인 장비를 선택합니다
df.select("device").where("signal > 10")
# 각 장비 타입에 대해 업데이트 횟수 세기
df.groupBy("deviceType").count()정적인 DataFrame/Dataset과 마찬가지로, 스트리밍 DataFrame/Dataset 역시 임시 뷰로 등록하여 SQL 명령을 실행할 수 있습니다.
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // 다른 스트리밍 DataFrame을 반환합니다df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") # 다른 스트리밍 DataFrame을 반환합니다DataFrame/Dataset이 스트리밍 데이터를 가지고 있는지 여부는 df.isStreaming를 이용하여 확인할 수 있음을 참고하시기 바랍니다.
df.isStreamingdf.isStreaming()이벤트 시각에 대한 윈도우 연산
구조화된 스트리밍에서의 이벤트 시각에 대한 슬라이딩 윈도우별 집계 연산은 그룹별 집계 연산과 매우 비슷하게, 직관적으로 표현할 수 있습니다. 그룹별 집계에서 집계 결과(예: 카운트)는 사용자가 그룹화를 위해 지정한 컬럼마다 유일하게 유지됩니다. 윈도우별 집계에서는 집계 결과가 해당 로우가 속하는 이벤트 시간 윈도우에 대해 유일하게 유지됩니다. 이를 실제 예시를 통해 알아보겠습니다.
이전에 살펴보았던 간단한 예제를 약간 바꿔서, 스트림이 라인과 각 라인의 생성 시간을 담고 있다고 해보겠습니다. 그냥 단어 수를 세는 것 대신 10분 윈도우까지의 단어 수를 세고, 이를 5분마다 갱신한다고 해 봅시다. 다시 말해, 여기서의 카운트는 10분 윈도우인 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20에 도착한 단어의 수를 의미합니다. 12:00 이후, 12:10 이전에 도착한 데이터가 12:00 - 12:10 윈도우에 포함됩니다. 이제, 12:07에 도착한 단어에 대해 생각해 봅시다. 이 단어는 12:00 - 12:10과 12:05 - 12:15에 해당하는 두 윈도우의 카운트를 증가시켜야 합니다. 따라서 그룹 키(=단어 그 자체)와 (이벤트 시각에서 계산될 수 있는) 윈도우 두 곳에 인덱스되어야 합니다.
결과 테이블은 다음과 같은 형태가 됩니다.
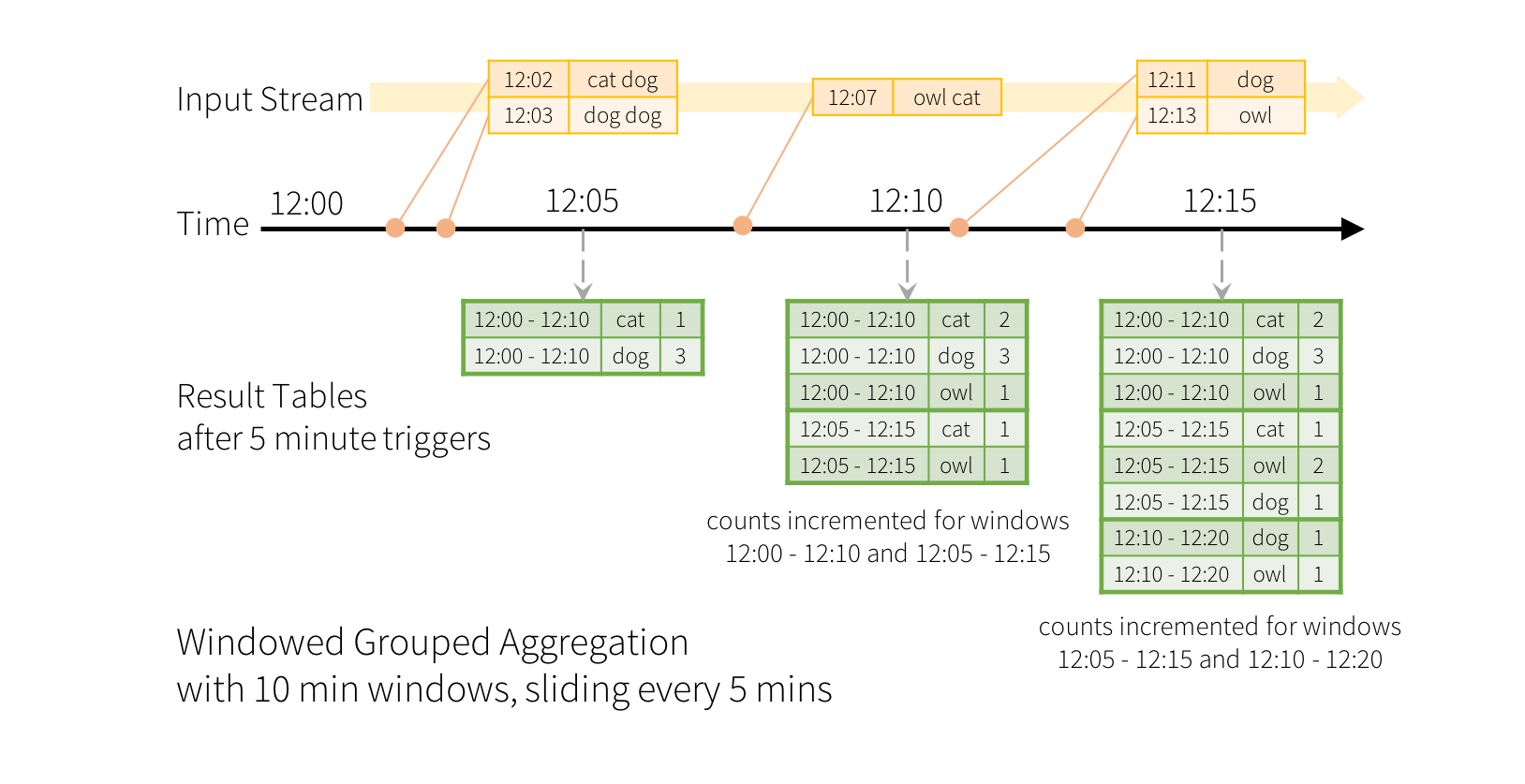
윈도윙(windowing, 혹은 윈도우화)과 그루핑(grouping, 혹은 그룹화)이 비슷한 방식이기 때문에, 코드에서 윈도우 기반의 집계를 표현하기 위해 groupBy()와 window() 를 사용할 수 있습니다. Scala/Java/Python으로 작성된 아래 예시에서 전체 코드를 살펴보세요.
import spark.implicits._
val words = ... // { timestamp: Timestamp, word: String }의 스키마를 갖는 스트리밍 DataFrame
// 데이터를 윈도우와 단어를 기반으로 그룹화 하고 각 그룹의 카운트를 계산한다
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()words = ... # { timestamp: Timestamp, word: String }의 스키마를 갖는 스트리밍 DataFrame
# 데이터를 윈도우와 단어를 기반으로 그룹화 하고 각 그룹의 카운트를 계산한다
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()지연된 데이터의 처리와 워터마크 지정
이벤트가 애플리케이션에 뒤늦게 도착하는 상황을 가정해 보겠습니다. 예를 들어, 12:04(이벤트 시간)에 생성된 단어가 12:11에 애플리케이션에 도착했다고 하면, 애플리케이션은 12:11이 아닌 12:04를 이벤트 시간으로 하여 예전 윈도우인 12:00 - 12:10의 카운트를 갱신하여야 합니다. 이는 윈도우 기반 그룹화 과정에서 자연스럽게 발생합니다. 구조적 스트리밍은 부분적으로 집계된 중간 상태를 오랜 기간 동안 유지할 수 있기 때문에, 아래 그림에서 보여지는 것과 같이 늦은 데이터를 예전 윈도우의 집계에 정확하게 반영할 수 있습니다.
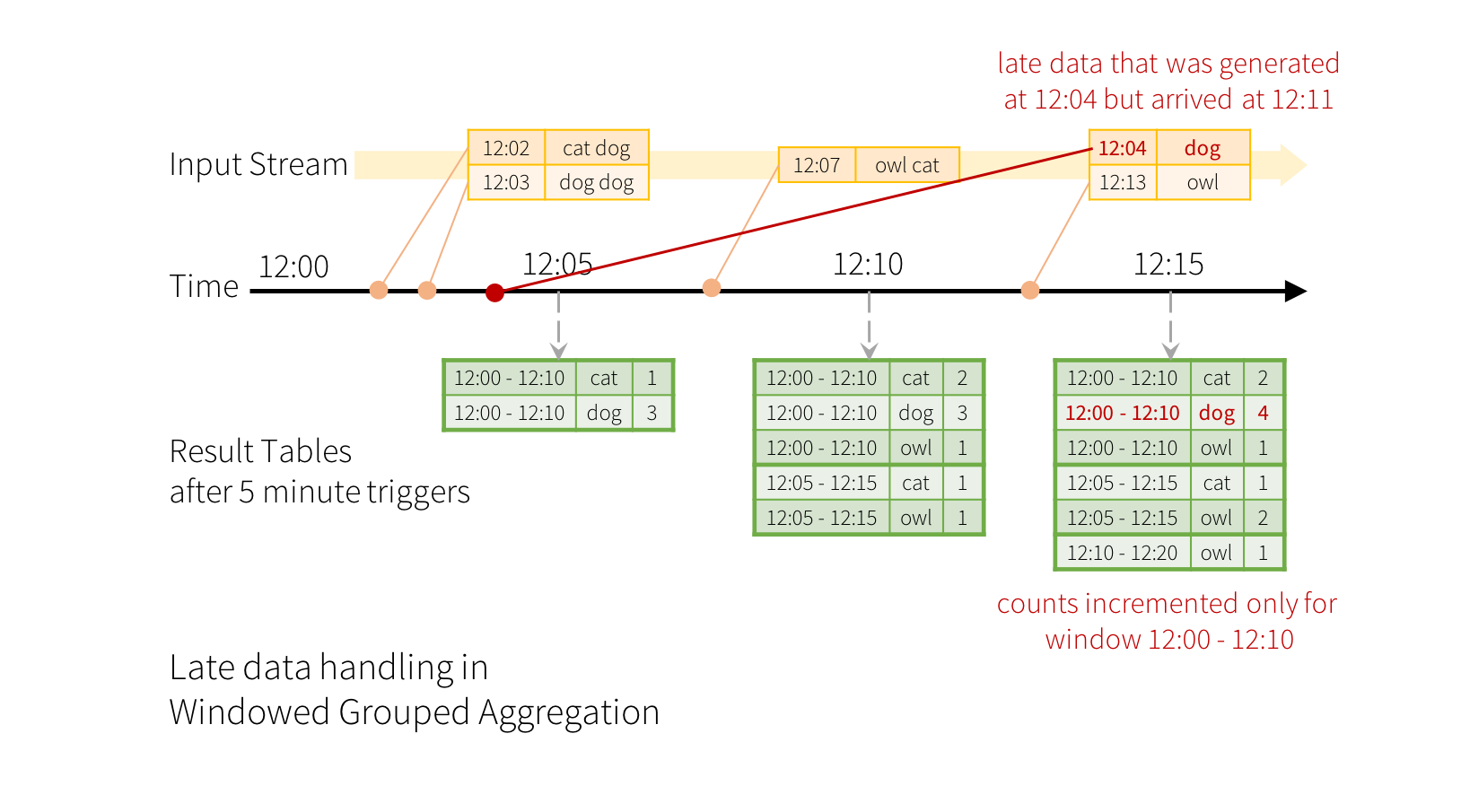
하지만 이와 같은 쿼리를 수일 동안 지속적으로 실행하려면, 메모리에 누적되는 중간 상태의 양을 시스템이 제한하여야 합니다. 즉, 애플리케이션이 임의의 집계 상태에 대해 지연된 데이터를 더이상 추가할 필요가 없으므로 메모리에서 이를 제거할 수 있게 되는 시점을 시스템이 판단할 수 있어야 하는 것입니다. 가능하게 하기 위해, 스파크 2.1 버전에서는 엔진이 자동으로 데이터의 현재 이벤트 시간을 추적하고 그에 따라 오래된 상태를 정리하는 워터마킹이 도입되었습니다. 이벤트 시간 컬럼과 데이터가 얼마나 늦을지에 대한 (이벤트 시간) 임계 값을 설정하여 쿼리의 워터마크를 지정할 수 있습니다. 시간 T에 시작하는 특정 윈도우에 대해, 엔진은 (엔진이 확인한 가장 늦은 이벤트 시간 - 지연 임계 값 > T)를 만족할 때까지 상태를 유지하고 지연된 데이터 업데이트를 허용합니다. 다시 말해, 임계 값 내에 해당하는 늦은 데이터는 집계가 되지만, 임계 값보다 늦은 데이터는 지워집니다. (보다 정확한 동작 보장에 대해서는 이 섹션의 후반을 참고하세요). 예제를 통해 알아보겠습니다. 이전 예제에서 withWatermark()를 이용해 아래와 같이 워터마크를 지정할 수 있습니다.
import spark.implicits._
val words = ... // { timestamp: Timestamp, word: String }의 스키마를 가지는 스트리밍 DataFrame
// 데이터를 윈도우와 단어를 기준으로 그룹화 하고 각 그룹의 카운트를 계산한다
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()words = ... # { timestamp: Timestamp, word: String }의 스키마를 가지는 스트리밍 DataFrame
# 데이터를 윈도우와 단어를 기준으로 그룹화 하고 각 그룹의 카운트를 계산한다
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()이 예제에서는 컬럼 “timestamp”에 워터마크를 지정하고, “10 minutes”를 임계 값으로 지정하여 얼마나 지연된 데이터까지 허용할지를 정의하고 있습니다. 이 쿼리가 (추후 출력 모드 섹션에서 설명할) Update 출력 모드로 실행된다면, 윈도우가 “timestamp” 컬럼의 현재 이벤트 시간에서 10분까지의 워터마크보다 오래되기 전까지는 엔진이 결과 테이블에 있는 카운트를 계속 업데이트합니다. 아래가 이를 설명한 그림입니다.
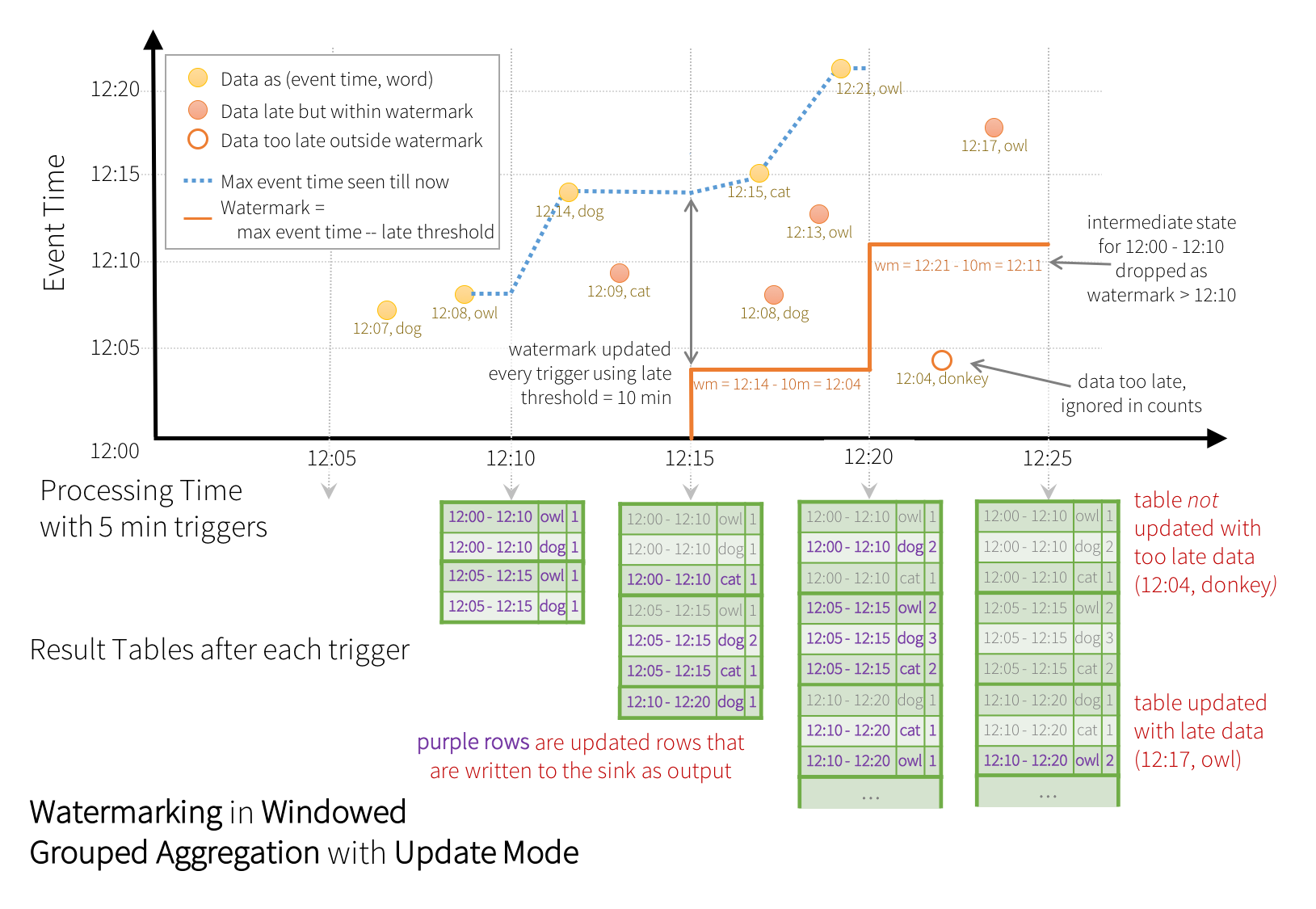
위의 그림에서 볼 수 있듯, 파란 점선이 엔진이 추적하는 최대 이벤트 시간이고, 붉은 선이 매 트리거 시작 전에 (최대 이벤트 시간 - '10 mins')으로 설정되는 워터마크입니다. 예를 들어, 엔진이 (12:14, dog)라는 데이터를 받았을 때, 다음 트리거에서의 워터마크는 12:04로 설정됩니다. 이 워터마크가 지정되면 다음 10분동안 추가적으로 늦은 데이터를 집계할 수 있도록 엔진이 중간 상태를 유지합니다. 예를 들어, 데이터 (12:09, cat)이 제 순서에 오지 않고 늦게 도달하였고, 윈도우 12:00 - 12:10과 12:05 - 12:15에 해당한다고 합시다. 그러면 12:09가 트리거에서의 워터마크인 12:04보다 아직 최신이기 때문에, 엔진이 중간 카운트를 상태로서 저장하고 있고 해당하는 윈도우를 알맞게 갱신할 것입니다. 하지만, 워터마크가 12:11로 갱신되었다면, 윈도우 (12:00 - 12:10)에 대한 중간 상태는 제거될 것이고, 모든 후속 데이터(예: (12:04, donkey))는 “매우 늦음”으로 간주되어 무시될 것입니다. 매 트리거 이후 갱신된 카운트(예: 보라색 로우)가 Update 모드에 서술된 대로 트리거 출력으로서 싱크(sink)에 작성됩니다.
일부 싱크(예: 파일)는 Update 모드에 필요한 세분화된 갱신을 지원하지 않을 수 있습니다. 이러한 싱크를 위해 _최종 카운트_만 싱크에 작성하는 Append 모드도 지원합니다. 이는 아래에서 설명됩니다.
withWatermark를 스트리밍이 아닌 Dataset에 사용하면 아무런 작업도 수행하지 않는다는 점에 주의하세요. 워터마크가 배치 쿼리에 대해 영향을 미쳐서는 안 되기 때문에 이를 바로 무시합니다.
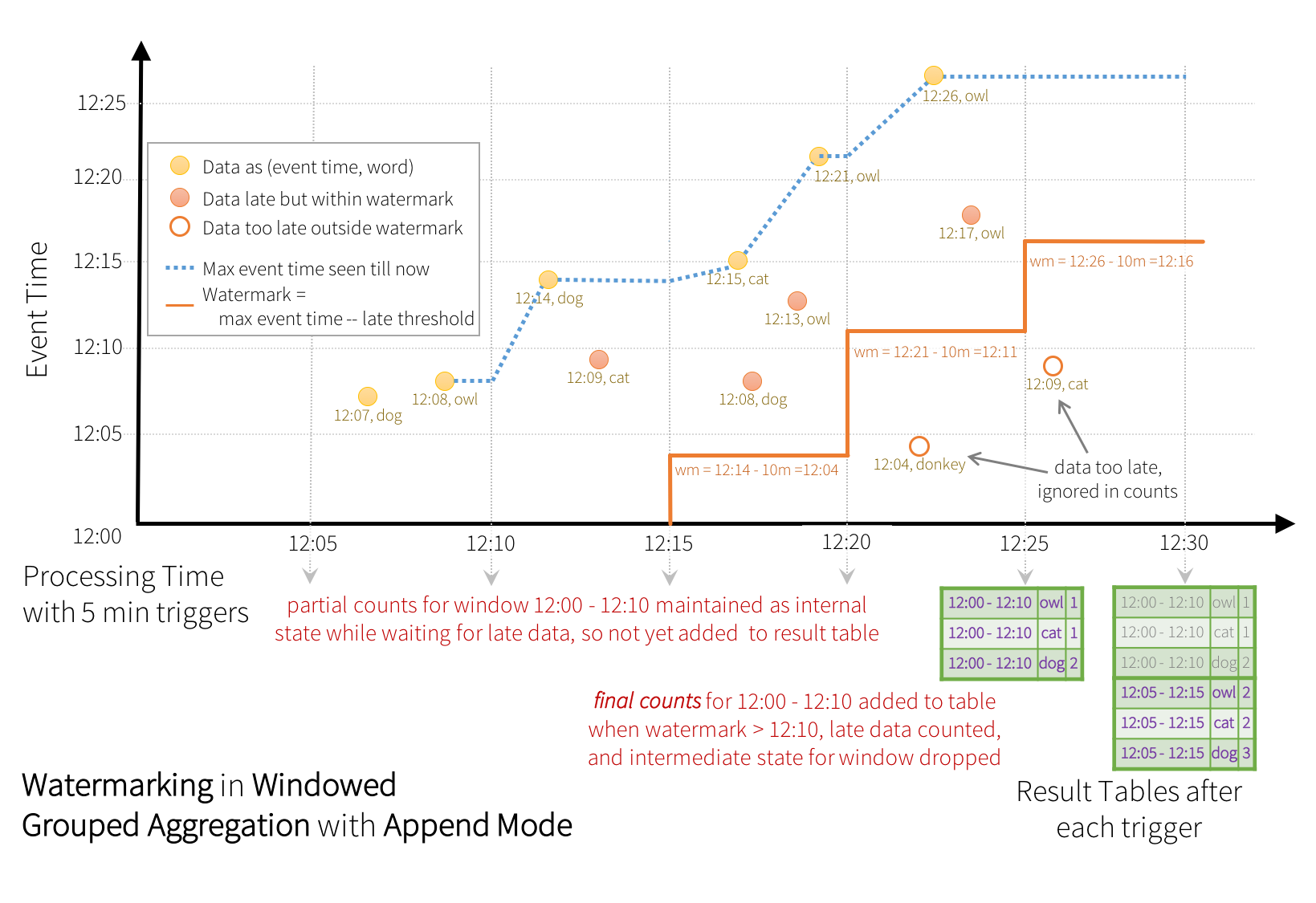
앞에서 언급한 Update 모드와 비슷하게, Append 모드에서도 엔진이 각 윈도우에 대해 중간 카운트를 유지합니다. 하지만, 부분적인 카운트는 결과 테이블에 갱신되지 않고 싱크에도 작성되지 않습니다. 엔진은 늦은 데이터가 카운트될 때까지 10분동안 대기하고, 워터마크보다 작은 윈도우의 중간 상태를 제거합니다. 그리고 최종 카운트를 결과 테이블과 싱크에 추가합니다. 예를 들어, 윈도우 12:00 - 12:10에 대한 최종 카운트는 워터마크가 12:11으로 갱신된 후에서야 결과 테이블에 추가됩니다.
집계 상태를 비우기 위한 워터마크 지정 조건
워터마크 지정시 다음 조건들이 충족되어야 집계 쿼리에서 상태를 비울 수 있습니다 (스파크 2.1.1 버전부터, 추후 변경될 수 있음).
-
출력 모드는 Append이거나 Update이어야 합니다. Complete 모드에서는 모든 집계 데이터가 보존되어야하므로 워터마크를 사용하여 중간 상태가 제거할 수 없습니다. 각 출력 모드가 어떠한 동작을 하는지 출력 모드 섹션에서 자세한 설명을 참조하세요.
-
집계는 이벤트 시간 컬럼 또는 이벤트 시간 컬럼에 대한 윈도우를 필요로 합니다.
-
withWatermark는 집계에서 사용된 timestamp 컬럼과 동일한 컬럼에 대해 호출되어야 합니다. 예를 들어,df.withWatermark("time", "1 min").groupBy("time2").count()는 집계 컬럼과 다른 컬럼에 대해 워터마크가 지정되었기 때문에 Append 출력 모드에서 유효하지 않습니다. -
withWatermark는 워터마크가 사용될 집계의 이전에 호출되어야 합니다. 예를 들어,df.groupBy("time").count().withWatermark("time", "1 min")는 Append 출력 모드에서 유효하지 않습니다.
워터마크가 지정된 집계의 동작 보장성
-
2시간 딜레이의 워터마크(
withWatermark로 설정된 워터마크)가 설정되면 2시간 내로 도착한 모든 데이터가 집계에서 누락되지 않는 것이 보장됩니다. 즉, 어떤 데이터든지 (이벤트 시간을 기준으로) 2시간을 지나지 않았다면 최신 데이터로 집계되는 것이 보장됩니다. -
하지만, 이 보장은 단방향으로만 성립합니다. 2시간보다 더 늦은 데이터가 집계가 되지 않음을 보장하지는 않습니다. 2시간보다 더 늦은 데이터는 집계가 될 수도, 되지 않을 수도 있습니다. 다만, 데이터가 지연되면 될 수록 엔진에서 처리할 가능성은 낮아집니다.
조인 연산
구조적 스트리밍은 스트리밍 Dataset/DataFrame을 정적 Dataset/DataFrame 또는 다른 스트리밍 Dataset/DataFrame과 조인하는 것을 지원합니다. 스트리밍 조인의 결과는 이전 섹션에서 살펴본 스트리밍 집계와 유사한 형태로 점진적으로 생성됩니다. 이 섹션에서는 위의 경우에서 어떠한 조인 연산(예: 내부 조인, 외부 조인 등)이 지원되는지 살펴보겠습니다. 지원하는 모든 조인에서, 스트리밍 Dataset/DataFrame과의 조인 결과는 동일한 스트림 데이터를 가지는 정적 Dataset/DataFrame과의 조인 결과와 같습니다.
스트림-정적 간 조인
스파크 2.0이 도입된 후로부터 구조적 스트리밍은 스트리밍과 정적 DataFrame/Dataset 간의 조인(내부 조인과 몇 가지 종류의 외부 조인)을 지원했습니다. 아래는 간단한 예시입니다.
val staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // 정적 DataFrame과의 내부 동등 조인
streamingDf.join(staticDf, "type", "right_join") // 정적 DataFrame과의 오른쪽 외부 조인staticDf = spark.read. ...
streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") # 정적 DataFrame과의 내부 동등 조인
streamingDf.join(staticDf, "type", "right_join") # 정적 DataFrame과의 오른쪽 외부 조인스트림과 정적 사이의 조인은 상태를 가지지 않기 때문에 상태 관리 역시 필요없습니다. 하지만, 일부 스트림-정적 외부 조인은 아직 지원되지 않습니다. 조인 섹션의 마지막 부분을 참조하세요.
스트림-스트림 간 조인
스파크 2.3 버전에서 스트림과 스트림 사이의 조인이 가능하게 되어 두 스트리밍 Dataset/DataFrame을 조인할 수 있게 되었습니다. 두 데이터 스트림의 조인 결과를 얻을 때의 어려운 점은 항상 두 dataset의 뷰가 완전하지 않기 때문에 두 입력 간의 매치를 찾기 어렵다는 것입니다. 한 쪽의 스트림 입력에서 받은 로우가 아직 수신되기 전의 다른 쪽의 스트림의 로우와 나중에 일치할 수도 있기 때문입니다. 그러므로 두 입력 스트림 모두에 대해 과거 입력을 스트리밍 상태로 버퍼에 저장하여, 모든 이후 입력을 과거 입력과 비교하여 조인 결과에 포함할 수 있도록 합니다. 또한, 스트리밍 집계와 마찬가지로 순서에 어긋난 늦은 데이터를 자동으로 처리하고 워터마크를 이용해 저장되는 중간 상태를 제한할 수 있습니다. 어떤 타입의 스트림-스트림 간 조인이 지원되는지 그리고 어떻게 이를 사용하는지 살펴보겠습니다.
선택적으로 워터마크가 지정된 내부 조인
모든 종류의 컬럼과 모든 조인 조건에 대해 내부 조인을 지원합니다. 그러나 스트림이 실행되면서, 새로 주어진 입력값이 이전의 입력값과 매치될 수도 있기 때문에, 잠재적으로 매치될 가능성이 있는 모든 이전 입력을 저장할 경우 스트리밍 상태의 크기는 계속해서 무한정 증가할 수밖에 없습니다. 이를 막기 위해, 무한히 오래된 입력은 나중에 들어올 입력과 매치되지 않게 스트리밍 상태에서 지워지도록 추가적으로 조인 조건을 지정해야합니다. 다시 말하면 조인에서 다음과 같은 추가 단계를 수행하여야 합니다.
-
(스트리밍 집계와 유사한 방법으로) 입력이 얼마나 지연될 수 있는지 엔진이 알 수 있도록 두 입력에 워터마크를 정의합니다.
-
한 입력의 오래된 로우가 다른 입력과의 매치에 필요하지 않게 되는 시점(즉, 시간 제약을 만족하지 않을 때)을 엔진이 알 수 있도록, 두 입력 모두에 해당하는 이벤트 시각에 대한 제약을 정의합니다. 이러한 제약은 다음 두 방법 중 하나로 정의할 수 있습니다.
-
시간 범위 조인 조건 (예:
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR), -
이벤트 시간 윈도우를 기준으로 조인 (예:
...JOIN ON leftTimeWindow = rightTimeWindow).
-
예제를 통해 살펴보도록 하겠습니다.
광고 노출이 수익 창출이 가능한 클릭을 발생시키는지 알아보기 위해, 광고 노출(광고가 사용자에게 보여졌을 때)에 대한 스트림과 사용자의 광고 클릭에 대한 스트림을 조인한다고 가정합시다. 이 스트림과 스트림 사이의 조인에서, 상태를 비우는 것을 허용하려면 다음과 같이 워터마킹 딜레이와 시간 제약을 설정해야 할 것입니다.
-
워터마크: 광고의 노출과 해당 광고 클릭의 이벤트 시간은 최대 각각 2시간과 3시간까지 지연되거나 순서에 맞지 않게 올 수 있다.
-
이벤트 시각: 광고의 노출 후, 해당 광고 클릭은 0초에서 1시간 사이에 발생한다.
코드는 다음과 같을 것입니다:
import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// 이벤트 시간 컬럼에 워터마크를 적용합니다
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// 이벤트 시각 제약을 설정하여 조인합니다
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)from pyspark.sql.functions import expr
impressions = spark.readStream. ...
clicks = spark.readStream. ...
# 이벤트 시간 컬럼에 워터마크를 적용합니다
impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
# 이벤트 시각 제약을 설정하여 조인합니다
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)워터마크가 지정된 스트림-스트림 간 내부 조인의 동작 보장성
이는 워터마크가 지정된 집계의 동작 보장성과 유사합니다. “2시간”의 워터마크 딜레이는 2시간 내에 도착한 데이터를 엔진이 절대로 누락하지 않는다는 것을 보장합니다. 하지만 2시간 이상 지연된 데이터에 대해서는 처리가 될 수도, 되지 않을 수도 있습니다.
워터마크가 지정된 외부 조인
워터마크와 이벤트 시간 제약이 내부 조인에서는 선택 사항이지만, 왼쪽 및 오른쪽 외부 조인에서는 반드시 지정되어야 합니다. 왜냐하면 외부 조인의 경우 결과로 NULL을 생성하려면 엔진이 입력 로우가 앞으로 어떤 것과도 매치되지 않을 것임을 확신할 수 있어야 하기 때문입니다. 그러므로 올바른 결과를 얻기 위해서는 워터마크와 이벤트 시간 제약 조건이 지정되어야 합니다. 그러므로, 외부 조인이 포함된 쿼리는 외부 조인을 명시하는 추가 파라미터를 제외하면 이전에 살펴본 광고 수익화 예제와 매우 비슷하게 보일 것입니다.
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // 가능한 값: "inner", "leftOuter", "rightOuter"
)impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # 가능한 값: "inner", "leftOuter", "rightOuter"
)워터마크가 지정된 스트림-스트림 간 외부 조인의 동작 보증성
워터마크 딜레이와 데이터가 누락될지 아닐지에 대해 외부 조인은 내부 조인과 동일하게 보장됩니다.
주의 사항
외부 조인의 결과 생성 방법과 관련하여 알아야 할 중요한 특징이 있습니다.
- 외부 조인 결과에서 NULL의 생성이 지연되는 정도는 지정된 워터마크 딜레이와 시간 범위 조건에 달려있습니다. 이는 엔진이 더 이상 일치하는 조건이 없을 때까지 해당 시간만큼 기다려야 하기 때문입니다.
- 마이크로 배치 엔진의 현재 구현에서, 워터마크는 마이크로 배치의 끝에서 시작되고, 다음 마이크로 배치에서 갱신된 워터마크를 이용해 상태를 정리하여 외부 조인의 결과를 출력합니다. 처리할 새 데이터가 있을 때에만 마이크로 배치를 사용하기 때문에, 스트림으로부터 아무런 데이터도 받지 못한다면 외부 조인의 결과 생성이 지연될 수 있습니다. 간단히 말해, 조인되고 있는 두 입력 스트림에서 한동안 아무런 데이터를 받지 못한다면, 외부 조인(왼쪽 및 오른쪽 조인 모두)의 결과 출력이 늦을 수 있습니다.
스트리밍 쿼리에서의 조인 지원 여부
| 왼쪽 입력 | 오른쪽 입력 | 조인 종류 | |
|---|---|---|---|
| 정적 | 정적 | 모든 종류 | 지원함, 스트리밍 쿼리 내에 존재할 수 있지만 스트리밍 데이터는 아니기 때문 |
| 스트림 | 정적 | 내부 | 지원함, 상태를 가지지 않음 |
| 왼쪽 외부 | 지원함, 상태를 가지지 않음 | ||
| 오른쪽 외부 | 지원하지 않음 | ||
| 전체 외부 | 지원하지 않음 | ||
| 정적 | 스트림 | 내부 | 지원함, 상태를 가지지 않음 |
| 왼쪽 외부 | 지원하지 않음 | ||
| 오른쪽 외부 | 지원함, 상태를 가지지 않음 | ||
| 전체 외부 | 지원하지 않음 | ||
| 스트림 | 스트림 | 내부 | 지원함, 선택적으로 워터마크를 양쪽에 지정하고 시간 제약을 둠으로써 중간 상태의 정리가 가능 |
| 왼쪽 외부 | 조건부로 지원함, 올바른 결과를 얻기 위해서는 반드시 워터마크를 오른쪽에 지정하고 시간 제약을 두어야 함, 모든 상태를 정리하기 위해 왼쪽에 워터마크를 선택적으로 지정할 수 있음 | ||
| 오른쪽 외부 | 조건부로 지원함, 올바른 결과를 얻기 위해서는 반드시 워터마크를 왼쪽에 지정하고 시간 제약을 두어야 함, 모든 상태를 정리하기 위해 오른쪽에 워터마크를 선택적으로 지정할 수 있음 | ||
| 전체 외부 | 지원하지 않음 | ||
지원되는 조인에 대한 추가 정보:
-
조인을 체인 형식으로 연결할 수 있습니다. 즉,
df1.join(df2, ...).join(df3, ...).join(df4, ....)와 같은 형태로 사용할 수 있습니다. -
스파크 2.3에서는 쿼리가 Append 출력 모드일 때만 조인을 사용할 수 있습니다. 다른 출력 모드는 아직 지원하지 않습니다.
-
스파크 2.3에서는 조인 전에 map 종류의 연산 이외의 것을 사용할 수 없습니다. 다음은 사용할 수 없는 몇 가지 예시입니다.
-
조인 전에 스트리밍 집계를 사용할 수 없습니다.
-
조인 전 Update 모드에서 mapGroupsWithState와 flatMapGroupsWithState를 사용할 수 없습니다.
-
스트리밍 중복 제거
이벤트의 고유 식별자를 사용하여 데이터 스트림의 중복 레코드를 제거할 수 있습니다. 이는 정적인 경우에서 고유 식별자 컬럼을 사용하여 중복을 제거하는 것과 동일합니다. 쿼리는 중복 레코드를 필터링할 수 있도록 이전 레코드 중 필요한 만큼의 데이터를 저장합니다. 집계와 마찬가지로, 워터마크의 유무와 관계없이 중복을 제거할 수 있습니다.
-
워터마크가 지정된 경우 - 중복 레코드가 얼마나 늦게 도착할지에 대한 상한선이 있는 경우, 이벤트 시각 컬럼에 워터마크를 지정하고, 해당 전역 고유 식별자(guid)와 이벤트 시간 컬럼을 이용하여 중복을 제거할 수 있습니다. 쿼리는 워터마크를 이용하여 더 이상 중복이 오지 않을 것이라고 생각되는 과거 레코드의 오래된 상태를 제거합니다. 이는 쿼리가 유지해야 하는 상태의 양을 제한합니다.
-
워터마크가 지정되지 않은 경우 - 중복 레코드가 언제 도착할지에 대한 범위가 없으므로, 쿼리는 모든 과거 레코드의 데이터를 상태로 저장합니다.
val streamingDf = spark.readStream. ... // 컬럼: guid, eventTime, ...
// 워터마크 없이 guid 컬럼을 이용
streamingDf.dropDuplicates("guid")
// 워터마크와 guid, eventTime 컬럼을 이용
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")streamingDf = spark.readStream. ...
# 워터마크 없이 guid 컬럼을 이용
streamingDf.dropDuplicates("guid")
# 워터마크와 guid, eventTime 컬럼을 이용
streamingDf \
.withWatermark("eventTime", "10 seconds") \
.dropDuplicates("guid", "eventTime")다중 워터마크 운용 정책
스트리밍 쿼리는 유니온(Union)되거나 조인된 여러 입력 스트림을 가질 수 있습니다. 상태 유지 연산을 위해 허용할 늦은 데이터에 대해 각 입력 스트림은 서로 다른 임계 값을 가질 수 있습니다. withWatermarks("eventTime", delay)를 이용하여 각 입력 스트림에 임계 값을 지정할 수 있습니다. 예를 들어, inputStream1과 inputStream2의 스트림-스트림 간 조인 생각해봅시다.
inputStream1.withWatermark(“eventTime1”, “1 hour”) .join( inputStream2.withWatermark(“eventTime2”, “2 hours”), joinCondition)
쿼리를 실행하는 동안, 구조적 스트리밍은 각 입력 스트림에서 확인된 가장 큰 이벤트 시간을 개별적으로 추적하고, 해당 지연을 기준으로 워터마크를 계산하고, 상태 유지 연산에 사용될 하나의 전역 워터마크를 선택합니다. 최솟값을 전역 워터마크로 정하게 되면 특정 스트림이 다른 스트림보다 뒤쳐지더라도 데이터가 누락되지 않는다는 것을 보장할 수 있기 때문에 (예: upstream 오류로 특정 스트림이 데이터 수신을 멈추는 경우), 기본값으로 최솟값이 전역 워터마크로 선택됩니다. 즉, 전역 워터마크는 가장 느린 스트림의 속도에 맞춰지고, 그만큼 쿼리의 결과가 지연되어 출력됩니다.
하지만 가장 느린 스트림의 데이터가 누락되더라도 빠른 결과를 얻고 싶을 수 있습니다. 스파크 2.4 버전부터 최댓값을 전역 워터마크로 선택하도록 복수 워터마크 처리 정책을 설정할 수 있습니다. SQL 환경 설정에서 spark.sql.streaming.multipleWatermarkPolicy를 max로 설정하세요 (기본값은 min입니다). 이를 설정하면 전역 워터마크가 가장 빠른 스트림의 속도로 맞춰집니다. 그러나 부작용으로 느린 스트림의 데이터가 적극적으로 누락됩니다. 그렇기 때문에 이 설정은 신중하게 사용되어야 합니다.
임의의 상태 유지 연산
많은 실제 사용 사례에서는 집계보다 더 고도의 상태 유지 연산이 요구되기도 합니다. 예를 들어, 이벤트의 데이터 스트림에서 세션을 추적하는 경우가 있습니다. 이런 세션화를 위해서는 임의 타입의 데이터를 상태로 저장하고, 매 트리거에서 데이터 스트림 이벤트를 사용해 상태에 임의의 연산을 수행해야 합니다. 스파크 2.2 버전부터는 mapGroupsWithState 연산과 더 강력한 연산인 flatMapGroupsWithState를 이용하면 됩니다. 두 연산은 그룹화된 Dataset에 사용자 정의 코드를 적용하여 사용자 정의 상태를 업데이트할 수 있도록 해 줍니다. 더 자세한 내용은 API 문서(Scala/Java)와 예제(Scala/Java)를 참조하세요.
지원하지 않는 연산
스트리밍 DataFrame/Dataset에서 지원되지 않는 DataFrame/Dataset 연산이 있습니다. 그 중 몇가지는 다음과 같습니다.
-
스트리밍 Dataset에서 다중 스트리밍 집계(예: 스트리밍 DataFrame의 연쇄적인 집계)는 아직 지원하지 않습니다.
-
스트리밍 Dataset에서 LIMIT 연산과 처음 N개의 로우를 가져오는 연산은 지원하지 않습니다.
-
스트리밍 Dataset에서 DISTINCT 연산은 지원하지 않습니다.
-
스트리밍 Dataset에서 정렬 연산은 집계 후에만, Complete 출력 모드에서 지원합니다.
-
스트리밍 Dataset에서 외부 조인은 거의 지원되지 않습니다. 자세한 내용은 조인 연산 지원 여부 섹션를 참조하세요.
이 외에도, 스트리밍 Dataset에 적용할 수 없는 Dataset 메소드가 있습니다. 이 액션 메소드들은 호출되는 즉시 쿼리를 실행하고 그 결과를 반환하기 때문에, 스트리밍 Dataset에서는 의미가 없는 메소드들입니다. 대신 이런 기능은 명시적으로 스트리밍 쿼리를 시작하여 수행할 수 있습니다 (이에 대해서는 다음 섹션을 참조하세요).
-
count()- 스트리밍 Dataset에서 하나의 카운트를 반환하는 것은 불가능합니다. 실행 카운트를 포함한 스트리밍 Dataset을 반환하는ds.groupBy().count()를 사용하세요. -
foreach()-ds.writeStream.foreach(...)를 사용하세요 (다음 섹션 참조). -
show()- 콘솔 싱크를 사용하세요 (다음 섹션 참조).
이러한 연산을 실행하면, “operation XYZ is not supported with streaming DataFrames/Datasets (연산 XYZ는 스트리밍 DataFrame/Dataset에 적용할 수 없습니다.)”라는 AnalysisException을 보게 될 겁니다. 이 중 일부는 후에 릴리즈될 스파크 버전에서 지원할 수도 있지만, 근본적으로 스트리밍 데이터에 대해 효율적으로 구현하는 것 자체가 어려운 연산도 있습니다. 예를 들어, 입력 스트림을 정렬하는 것은 지원하지 않는데, 스트림에 수신된 모든 데이터의 값을 확인해야 하기 때문입니다. 이는 효율적으로 실행하기가 근본적으로 어렵습니다.
스트리밍 쿼리 시작하기
최종 DataFrame/Dataset을 정의한 후에는 스트리밍 연산을 시작하면 됩니다. 이를 위해서는 Dataset.writeStream()을 통해 반환되는 DataStreamWriter(Scala/Java/Python 문서)를 이용하면 됩니다. 이 인터페이스에서 다음 중 하나 이상을 지정해야 합니다.
-
출력 싱크의 세부 사항: 데이터 형식, 위치 등.
-
출력 모드: 출력 싱크에 작성될 내용을 지정합니다.
-
쿼리 이름: (선택) 쿼리를 구분할 고유 이름을 지정합니다.
-
트리거 간격: (선택) 트리거의 간격을 지정합니다. 지정되지 않은 경우, 시스템은 이전 처리가 완료되자마자 새로운 데이터가 준비되었는지 확인합니다. 이전 처리가 완료되지 않아 처리 시간을 놓친 경우에는 시스템이 즉시 처리를 시작합니다.
-
체크포인트 위치: 종단간 장애 허용이 보장되는 일부 출력 싱크에 대해, 시스템이 체크포인트 정보를 작성할 위치를 지정합니다. 지정된 위치는 HDFS와 호환되는 장애 허용 파일 시스템 상의 디렉토리여야 합니다. 체크포인팅의 동작에 대해서는 다음 섹션에서 더 자세하게 설명됩니다.
출력 모드
출력 모드에는 몇 가지 종류가 있습니다.
-
Append 모드 (기본값) - 기본 모드입니다. 마지막 트리거 이후 결과 테이블에 새로 추가된 로우만 싱크로 출력됩니다. 이는 결과 테이블에 dlal 추가된 로우를 절대 변경하지 않는 쿼리에만 지원됩니다. 그러므로 이 모드는 각 로우가 한 번만 출력되는 것을 보장합니다 (장애 허용 싱크를 사용할 경우). 예를 들어
select,where,map,flatMap,filter,join등만 사용되는 쿼리에 한해 Append 모드를 지원합니다. -
Complete 모드 - 매 트리거 후에 전체 결과 테이블이 싱크로 출력됩니다. 이 모드는 집계 쿼리를 지원합니다.
-
Update 모드 - (스파크 2.1.1 버전부터 사용 가능) 마지막 트리거 이후 결과 테이블에서 업데이트된 로우만 싱크로 출력됩니다. 향후 릴리즈에서 더 많은 정보가 추가될 예정입니다.
각 스트리밍 쿼리는 서로 다른 출력 모드를 지원합니다. 다음은 호환성을 나타낸 표입니다.
| 쿼리 종류 | 지원하는 출력 모드 | 비고 | |
|---|---|---|---|
| 집계가 포함된 쿼리 | 워터마크가 지정된 이벤트 시각 기준 집계 | Append, Update, Complete |
Append 모드는 워터마크를 이용하여 오래된 집계 상태를 비웁니다. 단, 윈도우별 집계의 경우 withWatermark()에 지정된 지연 임계 값만큼 출력이 지연됩니다. 이는 로우가 최종적으로 결정되어야(즉, 워터마크를 지나면) 결과 테이블에 추가될 수 있는 식으로 모드가 동작하기 때문입니다. 자세한 내용은 늦은 데이터 섹션을 참고하세요.
Update 모드는 워터마크를 이용하여 오래된 집계 상태를 비웁니다. Complete 모드는 정의 자체가 결과 테이블의 모든 데이터를 보존한다는 이 모드의 의미이므로 오래된 집계 상태를 비우지 않습니다. |
| 기타 집계 | Complete, Update |
워터마크가 지정되지 않았기 때문에(다른 카테고리에서만 지정됨) 오래된 집계 상태는 비워지지 않습니다.
Append 모드의 정의 자체가 결과 업데이트를 할 수 있다는 집계 연산의 특성에 위배되므로 Append 모드는 지원하지 않습니다. |
|
mapGroupsWithState가 포함된 쿼리 |
Update | ||
flatMapGroupsWithState가 포함된 쿼리 |
Append 연산 모드 | Append |
flatMapGroupsWithState 다음에 집계가 허용됩니다.
|
| Update 연산 모드 | Update |
flatMapGroupsWithState 다음에는 집계가 허용되지 않습니다.
|
|
join이 포함된 쿼리 |
Append | Update와 Complete 모드는 아직 지원하지 않습니다. 지원되는 조인 종류에 대한 자세한 내용은 조인 연산 섹션의 지원 여부 표를 참조하세요. | |
| 기타 쿼리 | Append, Update | 모든 집계되지 않은 데이터를 결과 테이블에 유지하는 것이 불가능하기 때문에 Complete 모드는 지원하지 않습니다. | |
출력 싱크
내장된 출력 싱크에는 몇 가지 타입이 있습니다.
- 파일 싱크 - 출력을 디렉토리에 저장합니다.
writeStream
.format("parquet") // "orc", "json", "csv" 등이 될 수 있음
.option("path", "path/to/destination/dir")
.start()- Kafka 싱크 - 출력을 Kafka의 하나 이상의 토픽에 저장합니다.
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()- Foreach 싱크 - 출력의 레코드에 대해 임의의 연산을 실행합니다. 자세한 내용은 이 섹션의 후반부를 참조하세요.
writeStream
.foreach(...)
.start()- 콘솔 싱크 (디버깅용) - 트리거가 호출될 때마다 콘솔/표준 출력에 출력합니다. Append와 Complete 출력 모드 모두 지원합니다. 매 트리거 이후에 드라이버의 메모리에 출력 전체가 수집, 저장되기 때문에 적은 양의 데이터에 대해 디버깅 목적으로 사용되어야 합니다.
writeStream
.format("console")
.start()- 메모리 싱크 (디버깅용) - 출력이 메모리에 in-memory 테이블 형태로 저장됩니다. Append와 Complete 모드 모두 지원합니다. 모든 출력이 드라이버의 메모리에 수집, 저장되기 때문에 적은 양의 데이터에 대해 디버깅 목적으로 사용되어야 합니다.
writeStream
.format("memory")
.queryName("tableName")
.start()일부 싱크는 출력의 지속성을 보장하지 않으며 디버깅 목적으로 설계되었기 때문에 장애를 허용하지 않습니다. 장애 허용 의미 구조에 대한 이전 섹션을 참조하세요. 스파크에 내장되어 있는 모든 싱크에 대한 세부 사항은 다음과 같습니다.
| 싱크 | 지원하는 출력 싱크 | 옵션 | 장애 허용 | 비고 |
|---|---|---|---|---|
| 파일 싱크 | Append |
path: 출력 디렉토리의 경로, 반드시 지정되어야 함.
특정 파일 형식에 대한 옵션은 DataFrameWriter (Scala/Java/Python/R)에서 관련 메소드를 참조하세요. 예를 들어, “parquet” 형식에 대한 옵션은 DataFrameWriter.parquet()을 확인하세요.
|
예 (정확히 한 번) | 분할된 테이블에 쓰기를 지원합니다. 시간으로 분할하는 것이 유용할 수 있습니다. |
| Kafka 싱크 | Append, Update, Complete | Kafka 통합 가이드를 참조. | 예 (최소 한 번) | Kafka 통합 가이드에서 세부 사항을 참조. |
| Foreach 싱크 | Append, Update, Complete | None | ForeachWriter의 구현에 따라 다름. | 다음 섹션에서 세부 사항을 참조. |
| Foreach 배치 싱크 | Append, Update, Complete | 없음 | 구현에 따라 다름 | 다음 섹션에서 세부 사항을 참조 |
| 콘솔 싱크 | Append, Update, Complete |
numRows: 매 트리거에서 출력할 로우의 수. (기본값: 20)
truncate: 출력이 긴 경우 절삭 여부. (기본값: true)
|
아니오 | |
| 메모리 싱크 | Append, Complete | 없음 | 아니오. 하지만 Complete 모드에서 쿼리를 재시작하면 전체 테이블을 재작성합니다. | 테이블 이름이 쿼리 이름임. |
실제로 쿼리를 실행하려면 start()를 호출해야 한다는 것을 주의하세요. 이는 지속적으로 동작하는 쿼리 실행을 제어하는 StreamingQuery 객체를 반환합니다. 이 객체를 이용하여 쿼리를 관리할 수 있으며, 이는 다음 서브섹션에서 설명하겠습니다. 지금은 몇 가지 예시를 이용해 이를 이해해봅시다.
// ========== 집계가 없는 DataFrame ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// 새로운 데이터를 콘솔에 출력합니다
noAggDF
.writeStream
.format("console")
.start()
// 새로운 데이터를 Parquet 파일에 작성합니다
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== 집계가 있는 DataFrame ==========
val aggDF = df.groupBy("device").count()
// 업데이트된 집계를 콘솔에 출력합니다
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// 모든 집계를 in-memory 테이블에 저장합니다
aggDF
.writeStream
.queryName("aggregates") // 이 쿼리 이름이 테이블 이름이 됩니다
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // in-memory 테이블에서 대화식으로 쿼리합니다# ========== 집계가 없는 DataFrame ==========
noAggDF = deviceDataDf.select("device").where("signal > 10")
# 새로운 데이터를 콘솔에 출력합니다
noAggDF \
.writeStream \
.format("console") \
.start()
# 새로운 데이터를 Parquet 파일에 작성합니다
noAggDF \
.writeStream \
.format("parquet") \
.option("checkpointLocation", "path/to/checkpoint/dir") \
.option("path", "path/to/destination/dir") \
.start()
# ========== 집계가 있는 DataFrame ==========
aggDF = df.groupBy("device").count()
# 업데이트된 집계를 콘솔에 출력합니다
aggDF \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
# 모든 집계를 in-memory 테이블에 저장합니다. 쿼리 이름이 테이블 이름이 됩니다.
aggDF \
.writeStream \
.queryName("aggregates") \
.outputMode("complete") \
.format("memory") \
.start()
spark.sql("select * from aggregates").show() # in-memory 테이블에서 대화식으로 쿼리합니다Foreach와 ForeachBatch 사용하기
foreach와 foreachBatch 연산은 스트리밍 쿼리의 출력에 임의의 연산과 쓰기 로직을 적용 가능하게 합니다. 이 둘은 사용하는 경우가 약간 다릅니다. foreach는 사용자 정의 로직을 모든 로우에서 허용하는 반면, foreachBatch는 임의의 연산과 로직을 각 마이크로 배치의 출력에서 허용합니다. 각각의 자세한 사용법을 알아봅시다.
ForeachBatch
foreachBatch(...)를 사용하면 스트리밍 쿼리의 모든 마이크로 배치의 출력 데이터에 대해 실행될 함수를 지정할 수 있습니다. 스파크 2.4 버전부터 Scala, Java, Python에서 이를 지원합니다. 이 함수는 총 두 개의 매개변수로 마이크로 배치의 출력 데이터를 가진 DataFrame/Dataset과 마이크로 배치의 고유 식별자를 받습니다.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// 변환 후 배치 DataFrame을 작성합니다
}.start()def foreach_batch_function(df, epoch_id):
# 변환 후 배치 DataFrame을 작성합니다
pass
streamingDF.writeStream.foreachBatch(foreach_batch_function).start()foreachBatch를 이용하면 다음과 같은 작업을 할 수 있습니다.
- 기존 배치 데이터 소스의 재사용 - 많은 스토리지 시스템에서 아직 스트리밍 싱크를 이용할 수 없을 수도 있지만, 배치 쿼리를 위한 data writer는 이미 있을 것입니다.
foreachBatch를 사용하면 이를 각 마이크로 배치 출력에 배치 data writer를 이용할 수 있습니다. -
여러 위치에 쓰기 - 스트리밍 쿼리의 출력을 여러 위치에 쓰고 싶은 경우, 간단히 DataFrame/Dataset의 출력을 여러 번 쓸 수 있습니다. 하지만, 쓰기를 시도할 때마다 (입력 데이터부터 다시 읽는 것을 포함하여) 출력값을 새로 다시 계산할 가능성이 있습니다. 다시 계산되는 것을 막기 위해서는 출력 DataFrame/Dataset을 캐시해 두고, 이를 여러 위치에 쓴 후에, 캐시를 제거하면 됩니다. 대략 다음과 같습니다:
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) => batchDF.persist() batchDF.write.format(…).save(…) // location 1 batchDF.write.format(…).save(…) // location 2 batchDF.unpersist() }
- 추가적인 DataFrame 연산 적용 - 스트리밍 DataFrame에서 많은 DataFrame과 Dataset 연산이 지원되지 않습니다. 왜냐하면 여러 경우에서 스파크가 점진적 플랜 생성을 지원하지 않기 때문입니다.
foreachBatch를 사용하면 각 마이크로 배치 출력에 그 중 몇몇 연산을 적용할 수 있습니다. 하지만 이러한 연산을 왜 해야 하는지 그 종단간 의미에 대해서 잘 생각해 보셔야 합니다.
참고:
- 기본적으로
foreachBatch는 최소 한 번 이상의 쓰기가 이루어진다는 것을 보장합니다. 하지만 함수에 제공된 batchId를 이용하여 출력에서 중복을 제거하면 정확히 한 번만 이루어지도록 할 수 있습니다. foreachBatch는 근본적으로 스트리밍 쿼리의 마이크로 배치 실행에 의존하기 때문에, 지속 처리 모드에서 동작하지 않습니다. 데이터를 지속적인 모드에서 작성하기를 원하시는 경우,foreach를 사용하세요.
Foreach
foreachBatch를 사용할 수 없는 경우 (예를 들어, 해당하는 배치 data writer가 존재하지 않거나, 연속 처리 모드인 경우), foreach를 사용하여 직접 writer 로직을 표현할 수 있습니다. 명확히 말하자면, open, process, close의 세 가지 메소드로 분리하여 데이터 쓰기 로직을 작성할 수 있습니다. 스파크 2.4 버전부터 Scala, Java, Python에서 foreach를 지원합니다.
Scala에서는 클래스 ForeachWriter(문서)를 상속받아야 합니다.
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// 연결을 생성합니다
}
def process(record: String): Unit = {
// 연결에 string을 씁니다
}
def close(errorOrNull: Throwable): Unit = {
// 연결을 끊습니다
}
}
).start()Python에서는 foreach를 두 가지 방법으로 호출할 수 있습니다: 함수에서 혹은 객체에서. 이 함수는 처리 로직을 표현하는 간단한 방법을 제공하지만 오류로 인해 일부 입력 데이터가 재처리되어 발생하는 중복을 제거할 수는 없습니다. 이 경우 처리 로직을 객체 내부에 지정하는 방법을 써야 합니다.
- 이 함수는 로우를 매개변수로 받습니다:
def process_row(row):
# 스토리지에 로우를 씁니다
pass
query = streamingDF.writeStream.foreach(process_row).start()
- 이 객체는 process 메소드를 가지며, 선택적으로 open과 close 메소드를 가질 수 있습니다:
class ForeachWriter:
def open(self, partition_id, epoch_id):
# 연결을 생성합니다. 이 메소드는 Python에서 선택사항입니다.
pass
def process(self, row):
# 연결에 로우를 씁니다. 이 메소드는 Python에서 반드시 필요합니다.
pass
def close(self, error):
# 연결을 끊습니다. 이 메소드는 Python에서 선택사항입니다.
pass
query = streamingDF.writeStream.foreach(ForeachWriter()).start()
실행 의미 구조 스트리밍 쿼리가 시작되면 스파크는 지정된 함수나 객체의 메소드를 다음과 같은 방법으로 호출합니다:
-
이 객체의 단일 복사본은 쿼리의 하나의 작업에서 생성된 모든 데이터를 담당합니다. 즉, 하나의 인스턴스는 분산 방식으로 생성된 데이터의 한 파티션을 처리합니다.
-
이 객체는 직렬화가 가능해야 합니다. 왜냐하면 각 작업은 제공된 객체의 직렬화-역직렬화된 새 복사본을 제공받을 것이기 때문입니다. 그러므로, 데이터 작성을 위한 초기화(예: 연결 생성, 트랜잭션 시작)는 작업이 데이터를 생성할 준비가 되었음을 알리는 open() 메소드가 호출된 이후에 하는 것을 권장합니다.
-
메소드의 생명주기는 다음과 같습니다:
-
partition_id를 가지는 각 파티션:
-
epoch_id를 가지는 스트리밍 데이터의 각 배치/세대(epoch):
-
메소드 open(partitionId, epochId)이 호출됩니다.
-
open(…)이 true를 반환하면, 파티션과 배치/세대의 각 로우에 대해 메소드 process(row)가 호출됩니다.
-
로우를 처리하던 중 에러가 발생하면 메소드 close(error)이 호출됩니다.
-
-
-
-
만약 open() 메소드가 존재하고 성공적으로 반환된다면 (반환된 값은 상관없습니다), close() 메소드가 (존재한다면) 호출됩니다. JVM이나 Python 프로세스가 중간에 충돌하지 않는다면 호출되지 않을 수 있습니다.
-
참고: open() 메소드의 partitionId와 epochId는 오류로 인해 일부 입력 데이터의 재처리가 발생했을 때 생성된 중복 데이터를 제거하는 데 사용할 수 있습니다. 이는 쿼리의 실행 모드에 따라 다릅니다. 스트리밍 쿼리가 마이크로 배치 모드에서 실행되고 있다면, 고유 튜플 (partition_id, epoch_id)로 표현되는 모든 파티션이 동일한 데이터를 가지고 있는 것이 보장됩니다. 그러므로, (partition_id, epoch_id)를 이용해 중복 제거나 트랜잭션으로 커밋하여 정확히 한 번 데이터 처리를 보장 받을 수 있습니다. 이 둘을 동시에 하는 것도 가능합니다. 하지만, 스트리밍 쿼리가 연속 모드에서 실행되고 있다면, 이는 보장될 수 없기 때문에 중복 제거를 위해 사용해서는 안 됩니다.
트리거
스트리밍 쿼리의 트리거 설정은 스트리밍 데이터가 언제 처리될지,즉 쿼리가 고정된 배치 간격의 마이크로 배치 방식으로 실행될지 또는 연속 처리 방식으로 실행될지를 정의합니다. 다음은 지원되는 여러 타입의 트리거를 나타낸 표입니다.
| 트리거 타입 | 상세 |
|---|---|
| 지정되지 않음 (기본값) | 트리거 설정을 명시적으로 지정하지 않은 경우는 기본적으로 쿼리가 마이크로 배치 모드로 실행됩니다. 이 모드에서는 이전 마이크로 배치의 처리가 완료되는대로 다음 마이크로 배치가 생성됩니다. |
| 고정 간격 마이크로 배치 |
쿼리는 마이크로 배치 모드로 실행됩니다. 마이크로 배치는 사용자가 지정한 간격대로 실행됩니다.
|
| 일회성 마이크로 배치 | 쿼리는 모든 데이터를 처리할 오직 하나의 마이크로 배치만 실행하고 스스로 종료합니다. 이는 주기적으로 클러스터를 띄우고, 마지막 처리 구간 이후에 주어진 모든 데이터를 처리한 뒤 클러스터를 내리는 경우에 유용합니다. 특정한 상황에서는 이 방법으로 상당한 비용 절감이 가능할 수 있습니다. |
| 고정 체크포인트 간격으로 연속 (실험적 기능) |
쿼리는 새로운 낮은 지연의 연속 처리 모드로 실행됩니다. 이에 대한 더 자세한 내용은 아래의 연속 처리 섹션을 참고하세요. |
다음은 몇 가지 코드 예시입니다.
import org.apache.spark.sql.streaming.Trigger
// 기본 트리거 (마이크로 배치를 실행 가능한대로 바로 실행)
df.writeStream
.format("console")
.start()
// 2초 마이크로 배치 간격의 ProcessingTime 트리거
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
// 일회성 트리거
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start()
// 1초 체크포인트 간격의 연속 트리거
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()# 기본 트리거 (마이크로 배치를 실행 가능한대로 바로 실행)
df.writeStream \
.format("console") \
.start()
# 2초 마이크로 배치 간격의 ProcessingTime 트리거
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# 일회성 트리거
df.writeStream \
.format("console") \
.trigger(once=True) \
.start()
# 1초 체크포인트 간격의 연속 트리거
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()스트리밍 쿼리 관리
쿼리가 시작될 때 생성되는 StreamingQuery 객체를 이용하여 쿼리를 모니터링하고 관리할 수 있습니다.
val query = df.writeStream.format("console").start() // 쿼리 객체를 가져옵니다
query.id // 체크포인트 데이터에서 재시작되어도 일정하게 유지되는 고유 식별자를 가져옵니다
query.runId // 실행되는 쿼리의 고유 식별자를 가져옵니다. 이 식별자는 시작/재시작할 때마다 생성됩니다.
query.name // 자동 생성된 또는 사용자가 지정한 이름을 가져옵니다
query.explain() // 쿼리에 대한 자세한 정보를 출력합니다
query.stop() // 쿼리를 중지합니다
query.awaitTermination() // stop()이나 에러에 의해 쿼리가 종료될 때까지 대기합니다
query.exception // 쿼리가 에러에 의해 종료되는 경우에 발생하는 예외
query.recentProgress // 이 쿼리의 가장 최근 프로그레스 업데이트 정보를 저장한 배열
query.lastProgress // 이 스트리밍 쿼리의 가장 최근 프로그레스 업데이트query = df.writeStream.format("console").start() # 쿼리 객체를 가져옵니다
query.id() # 체크포인트 데이터에서 재시작되어도 일정하게 유지되는 고유 식별자를 가져옵니다
query.runId() # 실행되는 쿼리의 고유 식별자를 가져옵니다. 이 식별자는 시작/재시작할 때마다 생성됩니다.
query.name() # 자동 생성된 또는 사용자가 지정한 이름을 가져옵니다
query.explain() # 쿼리에 대한 자세한 정보를 출력합니다
query.stop() # 쿼리를 중지합니다
query.awaitTermination() # stop()이나 에러에 의해 쿼리가 종료될 때까지 대기합니다
query.exception() # 쿼리가 에러에 의해 종료되는 경우에 발생하는 예외
query.recentProgress() # 이 쿼리의 가장 최근 프로그레스 업데이트 정보를 저장한 배열
query.lastProgress() # 이 스트리밍 쿼리의 가장 최근 프로그레스 업데이트하나의 SparkSession에 여러 개의 쿼리를 시작할 수 있습니다. 쿼리들은 모두 클러스터의 자원을 함께 공유하며 실행됩니다. sparkSession.streams()를 사용하여 현재 활성 쿼리를 관리하는데 사용할 수 있는 StreamingQueryManager (Scala/Java/Python 문서)를 받아올 수 있습니다.
val spark: SparkSession = ...
spark.streams.active // 현재 활성 쿼리의 목록을 가져옵니다
spark.streams.get(id) // 고유 ID를 이용하여 쿼리 객체를 가져옵니다
spark.streams.awaitAnyTermination() // 실행 중인 여러 쿼리 중 어느 하나가 종료될 때까지 대기합니다spark = ... # 스파크 세션
spark.streams().active # 현재 활성 쿼리의 목록을 가져옵니다
spark.streams().get(id) # 고유 ID를 이용하여 쿼리 객체를 가져옵니다
spark.streams().awaitAnyTermination() # 실행 중인 여러 쿼리 중 어느 하나가 종료될 때까지 대기합니다스트리밍 쿼리 모니터하기
현재 동작중인 스트리밍 쿼리를 모니터링하는 방법에는 여러 가지가 있습니다. 스파크의 Dropwizard Metrics 지원을 이용하여 메트릭(Metrics)을 외부 시스템으로 푸시하거나 프로그래밍적으로 접근할 수 있습니다.
대화형으로 메트릭 읽어오기
streamingQuery.lastProgress()와 streamingQuery.status().lastProgress()를 이용해 현재 동작중인 쿼리의 상태와 메트릭을 직접 가져올 수 있습니다. lastProgress()는 Scala와 Java에서는 StreamingQueryProgress 객체를 반환하고, Python에서는 같은 필드를 가진 딕셔너리를 반환합니다. 반환값은 스트림에서 수행된 마지막 트리거의 모든 진행 정보(어떤 데이터가 처리되었는지, 처리 속도와 지연 속도는 어땠는지 등)를 가집니다. 마지막 몇 부분의 진행 정보만 배열로 반환하는 streamingQuery.recentProgress를 사용할 수도 있습니다.
또한, streamingQuery.status()는 Scala와 Java에서는 StreamingQueryStatus 객체를 반환하고 Python에서는 동일한 필드를 가진 딕셔너리를 반환합니다. 이는 현재 당장 쿼리가 어떤 작업을 하고 있는지에 대한 정보(트리거가 활성화되어 있는지, 데이터가 처리되고 있는지 등)를 제공합니다.
아래는 몇 가지 예시입니다.
val query: StreamingQuery = ...
println(query.lastProgress)
/* 다음과 같은 결과를 출력할 것입니다
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
println(query.status)
/* 다음과 같은 결과를 출력할 것입니다
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/query = ... # 스트리밍 쿼리
print(query.lastProgress)
'''
다음과 같은 결과를 출력할 것입니다
{u'stateOperators': [], u'eventTime': {u'watermark': u'2016-12-14T18:45:24.873Z'}, u'name': u'MyQuery', u'timestamp': u'2016-12-14T18:45:24.873Z', u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'sources': [{u'description': u'KafkaSource[Subscribe[topic-0]]', u'endOffset': {u'topic-0': {u'1': 134, u'0': 534, u'3': 21, u'2': 0, u'4': 115}}, u'processedRowsPerSecond': 200.0, u'inputRowsPerSecond': 120.0, u'numInputRows': 10, u'startOffset': {u'topic-0': {u'1': 1, u'0': 1, u'3': 1, u'2': 0, u'4': 1}}}], u'durationMs': {u'getOffset': 2, u'triggerExecution': 3}, u'runId': u'88e2ff94-ede0-45a8-b687-6316fbef529a', u'id': u'ce011fdc-8762-4dcb-84eb-a77333e28109', u'sink': {u'description': u'MemorySink'}}
'''
print(query.status)
'''
다음과 같은 결과를 출력할 것입니다
{u'message': u'Waiting for data to arrive', u'isTriggerActive': False, u'isDataAvailable': False}
'''프로그램 상에서 비동기 API를 이용한 메트릭 보고
StreamingQueryListener (Scala/Java 문서)를 사용하여 SparkSession과 관련된 모든 쿼리를 비동기적으로 모니터링 할 수도 있습니다. sparkSession.streams.attachListener()에 사용자가 정의한 StreamingQueryListener 객체를 등록하면, 쿼리가 시작 또는 중지되고 활성 쿼리가 진행될 때 콜백을 받게 됩니다. 다음은 예시입니다.
val spark: SparkSession = ...
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})Python에서는 지원하지 않음Dropwizard를 이용한 메트릭 보고
스파크는 Dropwizard 라이브러리를 사용하여 메트릭을 보고할 수 있도록 지원합니다. 구조적 스트리밍 쿼리의 메트릭도 함께 보고하기 위해서는, SparkSession에서 spark.sql.streaming.metricsEnabled 설정을 명시적으로 활성화해야 합니다.
spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
// 또는
spark.sql("SET spark.sql.streaming.metricsEnabled=true")spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
# 또는
spark.sql("SET spark.sql.streaming.metricsEnabled=true")이 구성이 활성화된 후 SparkSession의 모든 쿼리는 Dropwizard를 통해 메트릭을 사전에 구성된 싱크(예: Ganglia, Graphite, JMX 등)로 보고합니다.
체크포인트를 이용한 오류 복구
오류가 발생하거나 의도적인 종료한 경우에도 이전 진행 상태나 이전 쿼리의 상태를 복구하여 중단된 지점에서 이어서 진행할 수 있습니다. 이는 체크포인트와 로그 선행 기입(write-ahead logs)에 의해 수행됩니다. 쿼리를 정의할 때 체크포인트 위치를 지정할 경우, 쿼리는 모든 진행 정보(즉, 각 트리거에서 진행된 오프셋의 범위)와 실행 중인 집계(예: 빠른 예제에서 살펴보았던 단어 수)를 지정된 체크포인트 위치에 저장합니다. 이 체크포인트 위치는 HDFS 호환 파일 시스템의 경로이어야 하고, 쿼리를 시작할 때 DataStreamWriter의 옵션으로 지정할 수 있습니다.
aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()aggDF \
.writeStream \
.outputMode("complete") \
.option("checkpointLocation", "path/to/HDFS/dir") \
.format("memory") \
.start()스트리밍 쿼리에 변경점이 있을 때 복구의 동작
동일한 체크포인트 위치에서 재시작 시에 스트리밍 쿼리를 변경하는 경우에 몇 가지 제한 사항이 있습니다. 다음은 허용하지 않거나 변경의 효과가 명확하지 않은 몇 가지 종류의 변경입니다. 모든 경우에 대해:
-
‘허용한다’는 것은 해당 변경은 가능하지만 그 효과가 지니는 의미가 명확한지는 쿼리와 변경점에 따라 다르다는 것을 의미합니다.
-
‘허용하지 않는다’는 것은 재시작된 쿼리가 예측 불가능한 오류로 인해 실패할 가능성이 있으므로 해당 변경을 해서는 안 된다는 것을 의미합니다.
sdf는sparkSession.readStream으로 생성된 스트리밍 DataFrame/Dataset을 나타냅니다.
변경의 종류
-
입력 소스의 수 혹은 타입(즉, 다른 소스)의 변경: 허용하지 않습니다
-
입력 소스의 매개변수 변경: 이 변경이 허용되는지와 이 변경의 의미가 명확한지는 소스와 쿼리에 따라 달라집니다.
-
속도 제한의 추가/삭제/수정은 허용합니다:
spark.readStream.format("kafka").option("subscribe", "topic")에서spark.readStream.format("kafka").option("subscribe", "topic").option("maxOffsetsPerTrigger", ...)로의 변경 -
구독 중인(subscribed) 토픽/파일의 변경은 결과를 예측할 수 없기 때문에 일반적으로 허용하지 않습니다:
spark.readStream.format("kafka").option("subscribe", "topic")에서spark.readStream.format("kafka").option("subscribe", "newTopic")로의 변경
-
-
출력 싱크 타입의 변경: 몇몇 특정 싱크 간의 변경에서 허용합니다. 이는 각 케이스별로 확인이 필요합니다. 몇 가지 예시입니다.
-
파일 싱크에서 Kafka 싱크로의 변경은 허용합니다. Kafka에서는 새로운 데이터만 확인할 수 있습니다.
-
Kafka 싱크에서 파일 싱크로의 변경은 허용하지 않습니다.
-
Kafka 싱크에서 foreach나 그 반대 방향으로의 변경은 허용합니다.
-
-
출력 싱크의 매개변수 변경: 이 변경이 허용되는지와 잘 정의되는지는 싱크와 쿼리에 따라 달라집니다. 몇 가지 예시입니다.
-
파일 싱크의 출력 경로 변경은 허용하지 않습니다:
sdf.writeStream.format("parquet").option("path", "/somePath")에서sdf.writeStream.format("parquet").option("path", "/anotherPath")로의 변경 -
출력 토픽 변경은 허용합니다:
sdf.writeStream.format("kafka").option("topic", "someTopic")에서sdf.writeStream.format("kafka").option("topic", "anotherTopic")로의 변경 -
사용자 지정 foreach 싱크(즉,
ForeachWriter코드)의 변경은 허용되지만, 그 변경의 의미는 코드에 따라 달라집니다.
-
-
프로젝션 / 필터 / map 류 연산의 변경: 일부의 경우만 허용합니다. 예:
-
필터의 추가/삭제는 허용합니다:
sdf.selectExpr("a")에서sdf.where(...).selectExpr("a").filter(...)로의 변경 -
같은 출력 스키마일 때의 프로젝션의 변경은 허용합니다:
sdf.selectExpr("stringColumn AS json").writeStream에서sdf.selectExpr("anotherStringColumn AS json").writeStream로의 변경 -
출력 스키마가 다를 때의 프로젝션 변경은 조건적으로 허용합니다:
sdf.selectExpr("a").writeStream에서sdf.selectExpr("b").writeStream로의 변경은 출력 싱크가"a"에서"b"로의 스키마 변경을 허용하는 경우에만 허용합니다.
-
-
상태가 존재하는 연산의 변경: 스트리밍 쿼리의 일부 연산은 지속적으로 결과를 업데이트하기 위해 상태 데이터를 유지해야 합니다. 구조적 스트리밍은 자동으로 상태 데이터의 체크포인트를 장애 허용 스토리지(예: HDFS, AWS S3, Azure Blob 스토리지)에 생성하며, 재시작된 이후에는 이를 복원합니다. 단, 이 때 상태 데이터의 스키마가 재시작 전후로 같다고 가정합니다. 재시작 시에 스트리밍 쿼리에서 상태가 존재하는 연산의 변경(즉, 추가, 삭제, 스키마 변경)은 허용하지 않는다는 뜻입니다. 다음은 상태 복구를 보장하기 위해 재시작 시에 스키마가 변경되어서는 안 되는 상태가 존재하는 연산의 목록입니다:
-
스트리밍 집계: 예:
sdf.groupBy("a").agg(...). 그룹 키나 집계의 수 또는 타입의 변경을 허용하지 않습니다. -
스트리밍 중복 제거: 예:
sdf.dropDuplicates("a"). 그룹 키나 집계의 수 또는 타입의 변경을 허용하지 않습니다. -
스트림-스트림 간 조인: 예:
sdf1.join(sdf2, ...)(두 입력은sparkSession.readStream로 생성됨). 스키마나 동등 조인 시의 컬럼 변경은 허용하지 않습니다. 조인 타입(외부 혹은 내부)의 변경을 허용하지 않습니다. 다른 종류의 조인 조건 변경은 의미가 명확하지 않습니다. -
임의의 상태가 존재하는 연산: 예:
sdf.groupByKey(...).mapGroupsWithState(...)또는sdf.groupByKey(...).flatMapGroupsWithState(...). 사용자 정의 상태와 timeout의 타입의 스키마를 변경하는 것은 허용하지 않습니다. 사용자 정의 상태 매핑 함수의 변경은 허용하나, 이에 따른 의미는 사용자가 정의한 로직에 따라 다릅니다. 상태 스키마의 변경을 지원하고 싶은 경우, 스키마 마이그레이션을 지원하는 인코딩/디코딩 스키마를 이용하여 복잡한 상태 데이터 구조를 바이트로 명시적으로 인코딩/디코딩할 수 있습니다. 예를 들어, 이진 상태는 항상 성공적으로 복원될 수 있으므로, 상태를 Avro로 인코딩된 바이트로 저장하면 쿼리 재시작 시에 Avro 상태 스키마를 자유롭게 변경할 수 있습니다.
-
연속 처리 모드
[실험적 기능]
연속 처리 모드는 스파크 2.3 버전에서 추가된 새로운 스트리밍 실행 모드로서, 아직 실험적인 기능입니다. 이 모드는 지연 시간이 짧은 대신(~1ms) 장애 발생시 종단간 최소 한 번(at-least-once) 전달을 보장합니다. 이에 반해 기본 스트리밍 실행 모드인 _마이크로 배치 처리 모드 _는 종단간 정확히 한 번(exactly-once) 데이터 처리를 보장하지만, 지연 시간이 최대 100ms까지 걸릴 수 있습니다. (아래에서 다루는) 몇몇 쿼리 타입에서, 애플리케이션의 로직을 수정할 필요 없이 (즉, DataFrame/Dataset에서 호출되는 연산을 수정할 필요 없이) 쿼리의 실행 모드를 선택할 수 있습니다.
연속 처리 모드로 쿼리를 실행하려면 체크포인트 간격을 매개변수로 하여 연속형 트리거를 사용함을 명시해야 합니다. 예제는 아래와 같습니다:
import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("rate")
.option("rowsPerSecond", "10")
.option("")
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // 쿼리만 변경
.start()spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load() \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.trigger(continuous="1 second") \ # only change in query
.start()체크포인트 간격을 1초로 설정한 것은 연속형 처리 엔진이 1초마다 쿼리의 진행 상황을 기록한다는 것을 의미합니다. 이렇게 저장된 체크포인트 정보는 마이크로 배치형 처리 엔진과 호환되는 형식으로 저장되기 때문에, 어떠한 쿼리든 간에 트리거 설정과 상관없이 재시작 될 수 있습니다. 즉, 마이크로 배치 처리 모드에서 시작된 쿼리를 연속 처리 모드로 재시작할 수 있으며, 그 반대도 가능하다는 것입니다. 단, 연속 처리 모드로 전환할 경우 장애 발생시 (정확히 한 번(exactly-once)이 아니라) 최소 한 번(at-least-once) 전달이 보장된다는 점을 주의해야 합니다. (역자 주: 장애가 발생해도 종단 간에 정확히 한 번만 메시지가 전달되어야 하는 경우에는 연속 처리 모드로 재시작하면 안 된다는 의미입니다.)
지원되는 쿼리
스파크 2.3 에서의 연속 처리 모드에서는 아래와 같은 쿼리만 사용할 수 있습니다.
- 연산: 연속 처리 모드에서는 map 형태의 Dataset/DataFrame 연산만이 지원됩니다. 즉, 프로젝션 연산(projection;
select,map,flatMap,mapPartitions등)과 셀렉션 연산(selection;where,filter등)만이 사용 가능합니다.- 집계 함수,
current_timestamp(),current_date()를 제외한 모든 SQL 함수. 집계 함수는 단순히 아직 지원되지 않기 때문에, 나머지는 쿼리가 실행되는 시점에서야 값이 결정되기 때문에 사용할 수 없습니다.
- 집계 함수,
- 소스:
- Kafka 소스: 모든 옵션이 지원됩니다.
- Rate 소스: 테스트에 유용합니다. 단, 연속 처리 모드에서는
numPartitions과rowsPerSecond옵션만 지원합니다.
- 싱크:
- Kafka 싱크: 모든 옵션이 지원됩니다.
- 메모리 싱크: 디버깅에 유용합니다.
- 콘솔 싱크: 디버깅에 유용하며 모든 옵션을 지원합니다. 연속 처리 트리거에서 명시한 체크포인트 간격마다 콘솔에 결과가 출력됩니다.
자세한 내용은 입력 소스와 출력 싱크 항목에서 볼 수 있습니다. 콘솔 싱크가 테스트에 유용한 반면 Kafka 소스/싱크는 종단간 낮은 지연 처리 측면에서 가장 좋습니다. 입력 토픽에 데이터가 주어진 지 몇 밀리초 이내에 출력 토픽에서 결과를 확인할 수 있기 때문입니다.
주의사항
- 연속형 처리 엔진은 소스에서 데이터를 계속해서 읽어 와서 처리 결과를 싱크에 쓰는, 오랫동안 돌아가는 태스크(task)를 여럿 띄우는 방식으로 동작합니다. 쿼리를 실행하기 위해 띄워야 하는 태스크(task)의 수는 쿼리가 소스로부터 병렬로 데이터를 읽어들일 수 있는 파티션이 몇 개냐에 따라서 결정됩니다. 따라서 연속 처리 모드로 쿼리를 실행하기 전에, 클러스터가 모든 작업을 병렬로 수행할 수 있는 충분한 코어를 가지는지 확인해야 합니다. 예를 들어, 10개의 파티션을 가지는 Kafka 토픽에서 데이터를 읽어들일 경우, 클러스터가 최소한 10개의 코어를 가지고 있어야 쿼리를 실행할 수 있습니다.
- 연속 처리 스트림을 중지하면 작업 종료 경고가 발생할 수 있지만, 무시해도 상관 없습니다.
- 실패한 작업에 대한 자동 재시도는 아직 지원하지 않습니다. 작업이 실패하면 쿼리가 중단되며 체크포인트에서 수동으로 재시작해야 합니다.
기타 자료
더 읽어보기
- 직접 실행해볼 수 있는 Scala/Java/Python/R 예제
- 스파크 프로젝트에 포함된 예제 실행법
- 구조적 스트리밍 - Kafka 연동 가이드
- DataFrame/Dataset 의 구체적인 사용법은 스파크 SQL 프로그래밍 가이드를 참조.
- 외부 블로그 포스트
토크
- Spark Summit Europe 2017
- 스파크 구조적 스트리밍을 사용한 쉽고 확장성 있는 장애 허용 스트리밍 처리 - Part 1 slides/video, Part 2 slides/video
- 구조적 스트리밍에서의 상태 유지 스트리밍 처리 자세히 알아보기 - slides/video
- Spark Summit 2016
- 구조적 스트리밍 자세히 알아보기 - slides/video